이번 포스팅은 부스팅 알고리즘 중에서 Gradient Boosting에 대해 알아보도록 하겠습니다. GBM 알고리즘은 부스팅 할 때 Gradient(기울기)를 이용하기 때문에 붙여진 이름입니다.
그러면 알고리즘의 특징, Adaboost와 차이점, 동작 원리, 장단점, 하이퍼파라미터 튜닝 순으로 살펴보도록 하겠습니다.
✔️ 1편. 부스팅 알고리즘 역사와 종류
✔️ 2편. Adaboost 동작 원리
✔️ 3편. GBM 특징 및 동작 원리
✔️ 4편. Light GBM 특징 및 장단점
✔️ 5편. CatBoost 특징 및 동작 원리
✔️ 6편. XGBoost 특징 및 장단점
👉 시리즈는 순서대로 보면 더 유용해요!
GBM(Gradient Boosting)의 특징은?
Gradient Boosting은 다음 모델로 넘겨주는 input을 gradient(기울기)를 이용합니다. 그리고 그 값에 가중치를 부여하는 방식입니다. 모델들은 계속해서 잔차, 즉 실제값과 예측값의 차이를 줄여가는 방향으로 학습합니다.
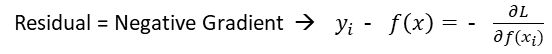
부스팅에서 이미 배웠듯이 Tree 1, 2, 3을 약한 분류기(weak learner)라고 한다면, 이를 결합한 분류기를 강한 분류기(strong learner)이라고 합니다.
보통 약한 분류기로 decision tree를 사용합니다. GBM은 잔차를 0으로 학습하는 방향으로 하기 때문에 정확도가 좋아 높은 성능을 보일 수 있지만, 동시에 과적합이 될 수 있는 가능성도 존재합니다.
그래서 GBM 기반 모델에는 정규화 알고리즘이 꼭 포함되어야 합니다. 예를 들어 learning_rate를 활용하여 정규화할 수 있는데, 예측값에 곱하여 예측값과 실제값과의 차이를 일부러 조금씩 남겨두는 방식 사용하기도 합니다.
AdaBoost vs GBM
AdaBoost는 약한 분류기로 Stump를 사용합니다. 여기서 Stump는 '나무 그루터기'를 뜻하며 한개 노드와 두 개 가지를 갖는 작은 tree를 말합니다. 반면에 Gradient Boosting에서는 성장이 제한된 tree를 사용합니다.
이것은 첫 번째 약한 분류기는 모든 샘플의 output 평균을 값으로 갖는 leaf를 생성합니다. 이때 모든 leaf는 불순도가 평균이 되게 생성합니다. 그다음은 output과 이전 모델의 예측치 사이의 오차(pseudo-residual)를 계산합니다.
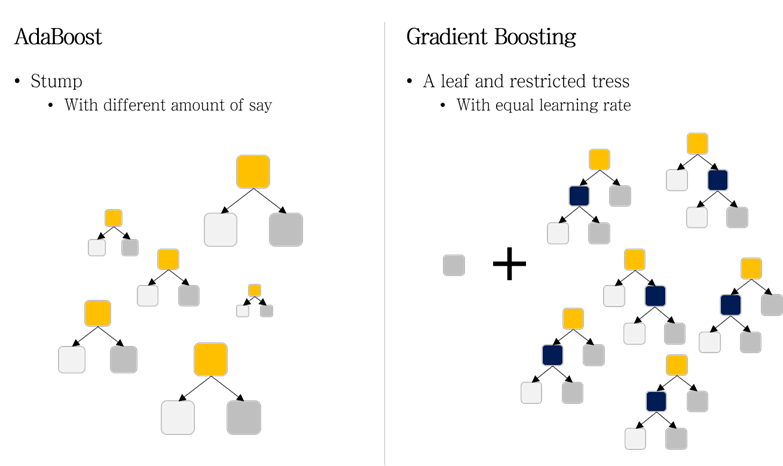
동작 원리
- Step 1 : Tree1은 트리 모델을 이용하여 fit한 모델을 생성
- Step 2 : Tree2는 tree1에서 나온 점(residual 값)을 fit 한 모델을 생성
- Step 3 : Tree3는 tree2의 나온 residual 값을 fit한 모델 생성
- Step 4 : Gradient boosting모델 = tree1 + tree2 + tree3
여기서 가중치 업데이터 방식은 경사하강법을 적용합니다. 핵심 아이디어는 모델링하고 놓친 부분이 residual이고 그것을 최소화하자는 것입니다.
장점
GBM은 머신러닝 계열의 모델 중 성능이 좋은 편입니다. 또 부스팅 계열 Tree 모델이 가지는 장점들을 가지고 있습니다. 수치형, 범주형 모두 예측 가능하고 결측 데이터 처리, 피처 중요도 선택이 쉽습니다.
단점
부스팅 모델이 아닌 배깅과 비교했을 때, 훨씬 속도가 느립니다. 그리드서치까치 할 경우 더 오랜 시간 소요됩니다. '잔차'를 줄여 나가기 위해 학습하는 부스팅 모델 특성상 오버피팅 발생 가능성이 높습니다. hp 튜닝에 시간이 많이 걸리고, 전문지식이 필요합니다. 부스팅 모델 특성상 해석이 어렵습니다.
하이퍼파라미터 튜닝
1. loss
- 경사 하강법에서 비용 함수를 지정합니다.
- 디폴트 값은 'deviance'입니다.
2. learning_rate
- 학습을 진행할 때마다 적용하는 학습률을 말합니다.
- 디폴트 값은 0.1 입니다.
- 너무 작으면 최소 오류 값을 찾지 못할 가능성 존재합니다.
- 너무 크면 최소 오류 값을 그냥 지나칠 가능성 존재합니다.
3. n_estimators
- 약한 학습기의 개수입니다.
- 순차적으로 오류를 보정하므로 많을수록 예측 성능이 일정 수준까지는 좋아질 수 있습니다.
- 디폴트 값은 100이며, 많을수록 시간이 오래걸립니다.
4. subsample
- 학습에 사용하는 샘플링 비율입니다.
- 디폴트 값은 1, 이는 전체 학습 데이터 기반으로 학습하는 것을 의미합니다.
- 예를 들어, 0.5는 학습 데이터의 50% 사용한다는 의미합니다.
- 과적합이 우려되는 경우 1보다 작은 값으로 설정합니다.
'데이터 분석' 카테고리의 다른 글
| Boosting 알고리즘 - CatBoost 특징(Ordered Boosting, Target Encoding 장단점) (0) | 2023.10.05 |
|---|---|
| Boosting 알고리즘 - Light GBM 특징(GOSS, EFB, 장단점) (2) | 2023.10.04 |
| Boosting 알고리즘 - Adaboost 동작 원리 (0) | 2023.09.24 |
| Boosting 알고리즘(AdaBoost, GBM, XGBoost, LightGBM, CatBoost) (0) | 2023.09.23 |
| 랜덤 포레스트(Random Forest) 장단점 - 특성(변수) 중요도 (0) | 2023.09.22 |



