이전 포스팅에서 Boosting 알고리즘에 대해 전반적인 개요을 알아보았습니다. 이번 포스팅에서는 에이다부스트(Adaboost)의 특징과 동작 원리를 알아 보겠습니다. 또한 장단점과 하이퍼파라미터 튜닝까지 살펴 보겠습니다.
AdaBoost 특징은?
AdaBoost은 Adaptive Boosting의 줄임말입니다. Adaptive(적응적) 학습을 한다는 의미로 진화생물학적 개념과 유사합니다. 각 단계에서 새로운 base learner를 학습하여 이전 단계의 base learner의 단점을 보완 합니다. Training error가 큰 관측치의 선택 확률(가중치)을 높이고, training error가 작은 관측치의 선택 확률을 낮춥니다. 이것은 오분류한 관측치에 보다 집중하기 위함입니다.
앞 단계의 조정된 확률(가중치)을 기반으로 다음 단계에서 사용될 training dataset 구성합니다. 다시 첫 단계부터 반복 후 최종결과물은 각 모델의 성능지표를 가중치로 하여 결합합니다. 하지만 GBM 계열 알고리즘이 더 성능이 뛰어나 잘 쓰이지 않는 알고리즘 입니다.
가중 평균(Weighted Average)
AdaBoost의 최종 예측은 각 약한 학습기의 예측 결과에 가중치를 부여하고 가중 평균을 내는 방식으로 이루어집니다. 다른 부스팅 알고리즘에서도 약한 학습기를 결합하지만, 가중 평균이나 다양한 결합 방식을 사용하지 않는 경우도 있습니다.
AdaBoost의 핵심 아이디어
- 초기에 모든 데이터 포인트에 동일한 가중치를 부여하고 첫 번째 약한 학습기를 학습시킵니다.
- 첫 번째 학습기의 결과를 기반으로 오분류된 데이터 포인트에 대한 가중치를 높입니다.
- 다음 약한 학습기는 업데이트된 가중치를 사용하여 학습됩니다.
- 이러한 과정을 반복하면서 약한 학습기를 연속적으로 학습합니다.
- 모든 약한 학습기의 결과를 가중 평균하여 최종 분류를 수행합니다.
이 아이디어를 실제 동작 원리로 살펴보면 아래와 같습니다.
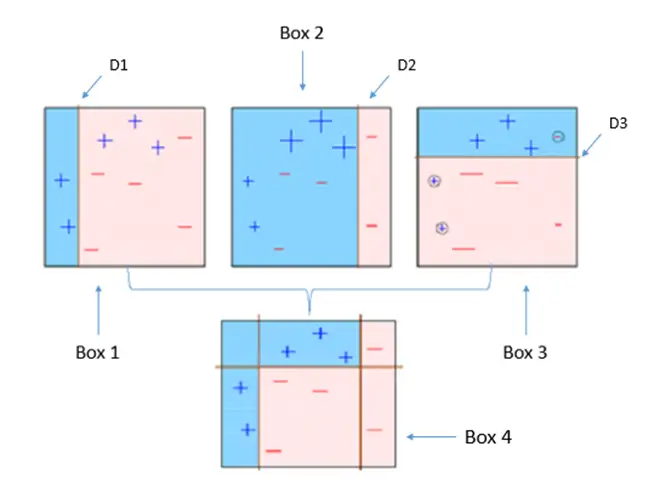
동작 원리
Step 1 : 첫 번째 약한 학습기가 첫번째 분류기준(D1)으로 + 와 - 를 분류
Step 2 : 잘못 분류된 데이터에 대해 가중치를 부여(두 번쨰 그림에서 커진 + 표시)
Step 3 : 두 번째 약한 학습기가 두번째 분류기준(D2)으로 +와 - 를 다시 분류
Step 4 : 잘못 분류된 데이터에 대해 가중치를 부여(세 번째 그림에서 커진 - 표시)
Step 5 : 세 번째 약한 학습기가 세번째 분류기준으로(D3) +와 -를 다시 분류해서 오류 데이터를 찾음
Step 6 : 마지막으로 분류기들을 결합하여 최종 예측 수행
장점
- AdaBoost는 상대적으로 구현이 쉽습니다.
- 과적합의 경향을 줄일 수 있습니다. 이건 앙상블 모델 특징이기도 합니다.
- 약한 학습기(weak learner)를 결합하여 강한 분류기(classifier)를 생성하여 방식. 즉, 실수 반복적으로 수정하여 정확도 향상시킵니다.
- Random Forest와 비교 시 대체로 학습 속도가 더 빠르고 결과 좋습니다.
단점
- AdaBoost는 노이즈 데이터나 이상치에 민감할 수 있습니다. 오분류된 데이터 포인트에 반복적으로 가중치를 부여하기 때문에 노이즈 데이터에 과적합할 가능성이 있습니다.
- XGBoost에 비해 상대적으로 느립니다. AdaBoost는 학습 단계가 순차적으로 진행되기 때문에 직렬 학습(Sequential Learning)입니다. 이로 인해 학습 시간이 다소 길 수 있습니다. 반면에 다른 부스팅 알고리즘 중 일부는 병렬 학습(Parallel Learning)을 지원하며, 여러 학습기를 병렬로 학습할 수 있습니다.
- 조정해야할 hyperparameter의 개수가 Random Forest에 비해 많습니다.
하이퍼파라미터 튜닝
- number of trees B : B개의 트리를 만들며, cross validation을 통해 B를 선택합니다.
- shrinkage parameter λ : Boosting 알고리즘이 학습하는 속도를 조절하는 파라미터로 0.01, 0.001을 주로 사용합니다.
- number of splits d : 트리의 크기를 결정하는 분기 개수 d는 작은 숫자로 설정합니다. 딱 한 개의 분기를 갖는 d=1이 잘 작동하는 경우도 많습니다.
AdaBoost는 분류 문제에서 주로 사용되며, 앙상블 학습의 초기 알고리즘 중 하나로 널리 알려져 있습니다. 이는 데이터의 불균형, 노이즈, 이상치 등 다양한 상황에서 뛰어난 예측 성능을 보이며, 다른 앙상블 알고리즘과 함께 현장에서도 활용되고 있습니다. 하지만 노이즈에 민감할 수 있고, 학습이 직렬적으로 이루어지는 단점이 있습니다. 다른 부스팅 알고리즘은 이러한 특징을 다르게 조정하여 다양한 상황에 적용됩니다.
'데이터 분석' 카테고리의 다른 글
| Boosting 알고리즘 - Light GBM 특징(GOSS, EFB, 장단점) (2) | 2023.10.04 |
|---|---|
| Boosting 알고리즘 - GBM(Gradient Boosting) 특징과 동작 원리 (0) | 2023.09.25 |
| Boosting 알고리즘(AdaBoost, GBM, XGBoost, LightGBM, CatBoost) (0) | 2023.09.23 |
| 랜덤 포레스트(Random Forest) 장단점 - 특성(변수) 중요도 (0) | 2023.09.22 |
| 랜덤 포레스트(Random Forest) 동작 원리 및 OOB, Random Subspace (0) | 2023.09.21 |



