이번 포스팅에서는 부스팅 알고리즘 중 가장 가벼운데 효율이 좋은 알고리즘인 Light GBM, 줄여서 LGBM에 대해 이야기해보겠습니다.
Light GBM은 데이터셋에 따라 다른 알고리즘 대비 속도가 너무 빨라 정상적으로 알고리즘이 돌아간 것 맞냐는 의문까지 서로 했던 기억이 있습니다.
✔️ 1편. 부스팅 알고리즘 역사와 종류
✔️ 2편. Adaboost 동작 원리
✔️ 3편. GBM 특징 및 동작 원리
✔️ 4편. Light GBM 특징 및 장단점
✔️ 5편. CatBoost 특징 및 동작 원리
✔️ 6편. XGBoost 특징 및 장단점
👉 시리즈는 순서대로 보면 더 유용해요!
LightGBM 특징
LightGBM은 부스팅 알고리즘 중에 2016년 출시로 비교적 최근에 만들어졌습니다. XGBoost보다 2년 후에 만들어지다 보니 XGBoost의 장점은 계승하고 단점은 보완하는 방식으로 개발 되었습니다.
Light Graient-Boosting Machine의 약자로 Microsoft에서 개발한 머신 러닝 무료 오픈 소스 프레임워크입니다. 앞에서 언급한 것처럼 기존 알고리즘의 정확도를 유지하면서 훨씬 좋은 효율성을 가지고 있는 LightGBM은 이름처럼 가볍다는 게 특징입니다.
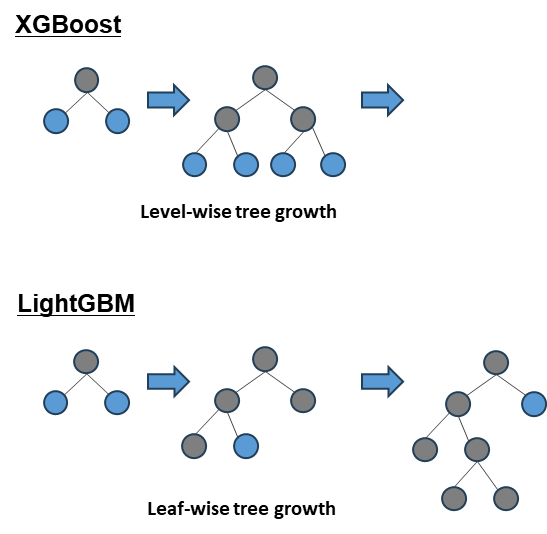
이렇게 가벼울 수 있는 이유는 기존 Boosting 알고리즘과 다르게 'Leaf-wise 트리 분할'을 하기 때문입니다. 이것은 트리의 균형을 맞추지 않고, 최대 손실값(max delta loss)을 가지는 리프 노드를 분할하여 예측 오류 손실을 최소화 합니다.
대신 트리의 깊이가 깊어지고 트리가 비대칭적이게 됩니다. 또 다른 특징은 카테고리형 피처의 자동 변환이 가능하고 최적 분할이 됩니다.
예를 들어, 원-핫 인코딩과 같은 범주형 변수를 수치형 변수로 바꿔주는 과정을 사용하지 않고도 범주형 변수를 최적으로 변환하고 이에 따른 노드 분할 수행이 이루어집니다.
XGBoost와 LightGBM 비교
두 알고리즘의 가장 큰 차이점은 노드 분할 방식이 다르다는 것입니다.
XGBoost
- 트리의 깊이를 효과적으로 줄이기 위한 균형 트리 분할 (Level-Wise)을 사용
- 최대한 균형 잡힌 트리를 유지하면서 분할하기 때문에 트리의 깊이가 최소화
- 균형 잡힌 트리를 생성하는 이유는 과적합을 방지할 수 있기 때문이나 균형을 맞추기 위한 시간이 오래 걸린다는 단점
LightGBM
- 리프 중심 분할 (Leaf-wise)은 트리의 균형을 맞추지 않고 최대 손실 값을 가지는 리프 노드를 지속적으로 분할
- 트리의 깊이가 깊어지고 비대칭적인 트리가 생성
- 손실값이 높은 노드에 대해 더 깊게 트리를 분할하며 손실값을 줄일 수 있기 때문에 더 좋은 정확도나 비슷한 수준의 성능 가능
두 알고리즘의 차이점에서 알 수 있는 것은 LightGBM이 다른 부스팅보다 메모리 사용량이 작다는 것입니다. 그런 이유로 알고리즘의 학습 시간은 GBM > XGBoost > LightGBM 순서로 시간도 적게 걸립니다.
히스토그램 기반 알고리즘
LightGBM은 히스토그램 기반 알고리즘입니다. 그래서 Split points라는 데이터가 분류되는 기준을 사용합니다. 예를 들어 키 > 180 을 기준으로 초과와 이하를 나누는 방식입니다.
연속된 변수들에 대해 분리된 칸에 담아 훈련(training) 시 각각의 변수들에 대해 Split을 이용한 히스토그램을 설계하는 매커니즘을 사용하는 것입니다.
GOSS = Gradient-based One-Side Sampling
GOSS는 LightGBM에서 경사를 기반으로 인스턴스를 다운 샘플링하는 방법을 말합니다. 경사가 작은 인스턴스는 잘 훈련되어 오류가 작고, 경사가 큰 인스턴스는 잘 훈련되지 않아 오류가 크다는 점을 활용하자는 아이디어입니다.
손실 함수에 가장 많이 기여하는 인스턴스를 샘플링하는 동시에 가장 기여하지 않는 인스턴스는 폐기합니다. 작동하는 방식은 아래와 같습니다.
- 경사의 절댓값을 기준으로 인스턴스를 내림차순 정렬합니다.
- 상위 a%의 인스턴스 선택 => 제대로 훈련되지 않은 데이터 정의합니다.
- 나머지 데이터인 b%개의 인스턴스 샘플링 => 충분히 훈련된 데이터의 기여도를 감소시킵니다.
- b를 제외한 a 샘플 만으로도 기존의 분포를 유지하기 위해 덜 훈련된 샘플들을 (1-a)/b 만큼 강조시킵니다.
EFB = Exclusive Feature Bundling
LightGBM에서 사용하는 EFB는 특성 수를 다운 샘플링해 학습 속도를 증가시키는 방법입니다. 일반적으로 고차원 데이터로 작업할 때, 상호배반적인 특성들을 번들링 합니다.
상호배반적이라는 것은 One-hot encoding에서 0이 아닌 값을 동시에 갖는 경우가 매우 드물다는 현상을 말합니다. 상호배반일 때 이러한 특성들을 번들링 하는 방식입니다. 결국 번들링을 통해 복잡도를 줄일 수 있습니다.
장점
- 실제 개인적인 사례에서도 체감했지만 학습하는데 걸리는 시간이 적게 걸립니다.
- 메모리 사용량이 상대적으로 적은편입니다.
- Categorical feature들의 자동 변환과 최적 분할이 가능합니다.
- GPU 학습을 지원합니다.
단점
사실 LightGBM은 거의 단점이 없습니다. XGBoost와의 예측 성능 차이가 크게 나지도 않습니다. 하지만 적은 데이터셋에 적용 시 과적합이 발생하기 쉽다는 것이 단점입니다.
여기서 '적은 데이터셋'이라 함은 통상적으로 10,000건 이하의 데이터셋 정도라고 LightGBM 공식 도큐먼트에 나와 있습니다.
하이퍼파라미터 튜닝
모델 복잡도 제어 :
- num_leaves 개수 조정
- 높으면 정확도가 높아지지만, 트리의 깊이가 깊어지고 모델이 복잡해짐
Overfitting 제어 :
- min_child_samples(최소한의 샘플수) 높이고 num_leaves와 max_depth 조정, reg_lambda(L2 정규화)와 reg_alpha(L1 정규화) 적용
성능 높이기 :
- learning_rate 작게 하면서 n_estimators 크게 하기
- 단, 시간이 오래 걸리고 overfitting될 가능성도 있음 -> 오히려 성능이 저하될 수 있으니 주의해야 함
'데이터 분석' 카테고리의 다른 글
| [머신러닝] 차원 축소(Dimensionality Reduction) 이유 및 방법 (1) | 2023.10.06 |
|---|---|
| Boosting 알고리즘 - CatBoost 특징(Ordered Boosting, Target Encoding 장단점) (0) | 2023.10.05 |
| Boosting 알고리즘 - GBM(Gradient Boosting) 특징과 동작 원리 (0) | 2023.09.25 |
| Boosting 알고리즘 - Adaboost 동작 원리 (0) | 2023.09.24 |
| Boosting 알고리즘(AdaBoost, GBM, XGBoost, LightGBM, CatBoost) (0) | 2023.09.23 |



