이번 포스팅은 부스팅 알고리즘에 대해 이야기 해보겠습니다. Boosting 알고리즘은 최근 Kaggle 대회에서 Deep Learning 다음으로 높은 수상 비중을 차지하고 있습니다. 그 이유는 우선 다른 모델보다 정확도가 비교적 높으며, 회귀(Regression), 분류(Classification), 순위 학습(Ranking), 텍스트 분석(NLP), 이미지 분석 등 여러가지 머신 러닝 문제를 해결하는데 사용됩니다.
다양한 오픈 소스 라이브러리와 도구를 활용할 수 있습니다. XGBoost, LightGBM, CatBoost 등이 Kaggle에서 특히 인기 라이브러리들 입니다. 또 부스팅 알고리즘은 병렬 처리와 GPU를 효과적으로 활용할 수 있는 모델 중 하나입니다. 이제 Boosting 알고리즘에 대해 하나씩 살펴 보겠습니다.
Boosting 알고리즘이란?
Boosting 알고리즘의 아이디어는 하나의 모델이 데이터에 overfitting되지 않게 약한 모델을 여러 개 결합시켜 그 결과를 종합해 보자는데에서 출발했습니다. 배깅은 개별 모델이 독립적이게 작동합니다. 이후 병렬 결과를 합치는 방식인 반면 부스팅은 특정 모델의 결과를 다른 모델의 input으로 사용하는 방식입니다.
모델간 단계별 가중치를 부여하여 결과를 산출 합니다. 여러 개의 Learning 모델을 순차적으로 구축하여 최종적으로 합치는 과정을 거칩니다. 이것을 Sequential Ensemble이라고 합니다. 여기서 사용되는 Learning 모델은 매우 단순한 모델을 사용합니다. 그것이 Tree 모델을 사용하는 이유입니다.
각 단계에서 새로운 base learner를 학습하여 이전 단계의 base learner의 단점을 보완해 나갑니다. 단계를 거치면서 모델이 점점 강해지게 됩니다. Boosting이란 말이 그래서 나오는 겁니다. Bagging과 Boosting의 성능을 비교하면, Boosting이 통상 성능이 더 좋지만, 소요되는 시간이 오래 걸리고 연산량도 많습니다. 두 방식을 비교한 아래 표를 참조해 주세요.
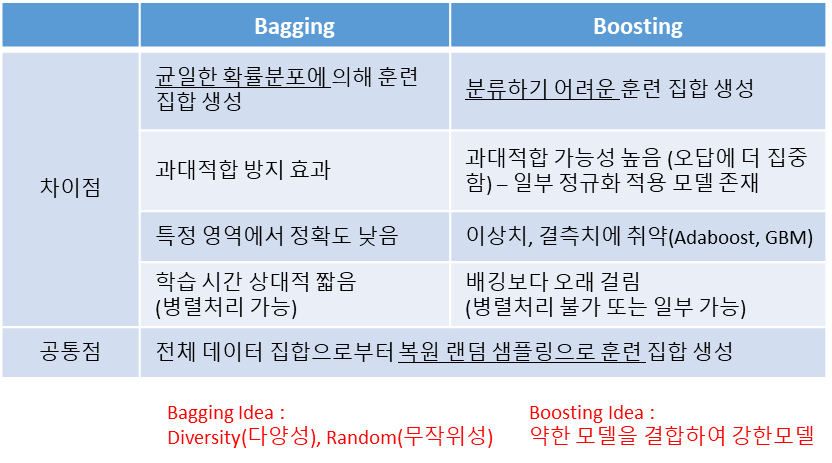
Boosting 알고리즘 역사 및 동향
- 1997’ : AdaBoost – Freund와 Robert Schapire가 개발하였으며 첫번째 부스팅 알고리즘
- 1999’ : Gradient Boosting(GBM) – Friedman이 소개한 알고리즘으로 미분 가능한 손실 함수를 사용, AdaBoost를 더 확장(순위 등 가능)
- 2001’ : Random Forest – Bagging 알고리즘
- 2014’ : XGBoost – Tiangi Chen(중국인) & Carlos Guestrin의 논문, Gradient Boosting의 최적화
- 2017’ : LightGBM – Microsoft는 대규모 데이터 세트를 처리하도록 설계
- 2018’ : CatBoost – Yandex, 범주형 기능을 처리하도록 설계
- 그 이후 : 캐글 대회에서 Boosting 과 딥러닝 두가지 접근 방법이 주류를 이룸
Boosting 동작 원리
Step 0 : 일단 y를 예측하는 learner(모델 H)을 만듭니다.
Step 1 : 모델 H의 성능을 판단합니다.(Square error, 손실함수 등)
Step 2 : 모델 H의 성능을 보강할 수 있는 새로운 weak learner H를 만들고 성능을 판단합니다. 이때 성능에 따라 가중치를 부여합니다.
Step 3 : 모든 weak learner의 weighted sum을 strong learner H로 정의합니다.
Step 4 : 모델 H의 성능이 만족스러울 때까지 1~3을 반복합니다.
Boosting이 학습하고 뭐가 다를까?
머신러닝 학습은 모델(방정식)을 만들기 위해 sample을 반복적 수행을 통해 가중치를 update 합니다. 하지만 boosting은 샘플링된 데이터를 순차적으로 모델을 보완해 가는 방식으로 가중치를 update 합니다.
딥러닝과 차이는 Boosting은 분산처리(미니배치) 아니고 순차적 처리를 진행합니다. bagging이 아닌 Pasting 방식입니다.
Boosting 모델 특징
- 향상된 정확도와 견고성 : 노이즈와 이상치에 대해 견고(robust) 합니다.
- 다양성 : 분류, 회귀, 순위, 추천 시스템, 시계열 예측 까지 다양한 예측이 가능합니다.
- 해석 가능성 : AdaBoost 같은 알고리즘은 본질적으로 해석이 가능하기도 합니다.
- 확장성 : XGBoost, LightGBM 등 확장성이 뛰어나, 대규모 데이터를 쉽게 처리할 수 있습니다.
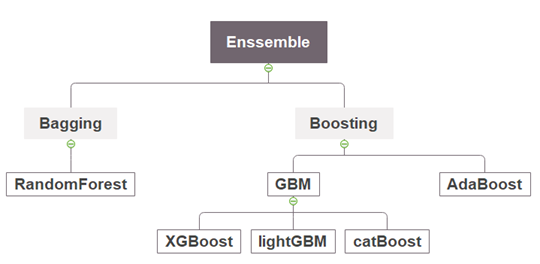
Boosting 모델 종류
Boosting 모델은 크게 두가지로 분류할 수 있습니다.
- AdaBoost(Adaptive Boosting, 에이다 부스트) : 모델이 예측에 실패한 샘플이 다시 학습될 수 있도록 weight 부가하는 방식으로 sampling하는 기법입니다.
- GBM(Gradient Boosting) : y로 학습하는 것이 아니라 잔차를 Label로 설정하여 학습하는 기법입니다. GBM, XGBoost, LightGBM, Catboost가 이에 해당합니다.
'데이터 분석' 카테고리의 다른 글
| Boosting 알고리즘 - GBM(Gradient Boosting) 특징과 동작 원리 (0) | 2023.09.25 |
|---|---|
| Boosting 알고리즘 - Adaboost 동작 원리 (0) | 2023.09.24 |
| 랜덤 포레스트(Random Forest) 장단점 - 특성(변수) 중요도 (0) | 2023.09.22 |
| 랜덤 포레스트(Random Forest) 동작 원리 및 OOB, Random Subspace (0) | 2023.09.21 |
| 랜덤 포레스트(Random Forest) 특징 - 앙상블 (0) | 2023.09.20 |



