이번 포스팅에서는 차원 축소(Dimensionality Reduction)에 대해 알아보도록 하겠습니다. 차원 축소는 무엇이고 왜 차원 축소를 해야하는지, 그리고 그 효과와 차원 축소 방법까지 알아보도록 하겠습니다.
차원 축소는 데이터 분석의 하나의 절차로 무조건 해줘야 하는 것으로 인식하는 경우도 있습니다. 하지만 차원 축소가 유리한 경우가 있고 필요가 없는 알고리즘도 있습니다. 이번 주제를 제대로 알게되면 그 궁금증이 풀릴 것입니다.
차원 축소(Dimensionality Reduction)
차원 축소는 고차원의 데이터로부터 저차원의 데이터로 변환하는 방법을 말합니다. 일반적으로 데이터 전처리 후 고려하는 단계로 특성 선택(Feature selection)과 특성 추출(Feature extraction) 두 가지가 있습니다. 벡터의 원소의 수(벡터의 차원)을 결국 Feature의 수를 말합니다.
이론적으로는 변수간 독립성 만족시 변수의 수가 증가할수록 모델의 성능이 향상합니다. 변수간의 독립성이 크다는 것은 각 변수가 포지션이 겹치지 않고 자기역할을 잘 하고 있다고 해석됩니다. 하지만 실제 상황에서는 변수간 독립성 가정 위배, 노이즈 존재 등으로 인해 변수의 수가 일정 수준 이상 증가하면 모델의 성능이 저하되는 경향이 있습니다. 이것을 '차원의 저주'라고 부룹니다.
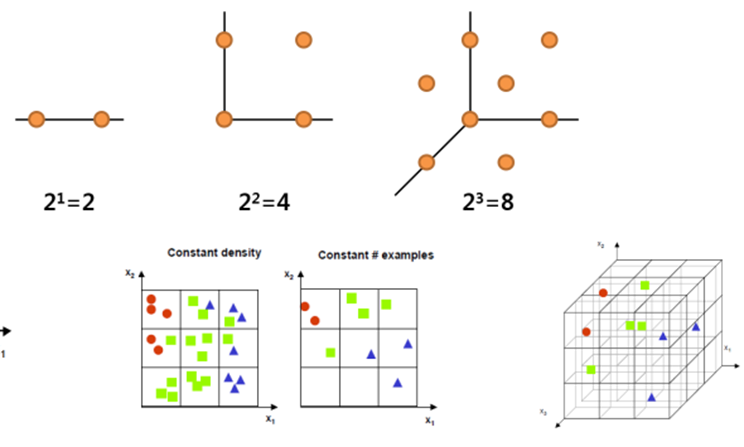
차원의 저주
차원의 저주는 과거 포스팅에서도 설명한 적이 있어 간단하게 설명하고 넘어가겠습니다. 동등한 설명력을 갖기 위해서는 변수(차원)가 증가할 때 필요한 개체의 수(dataset 수)는 기하급수적으로 증가합니다. 동일한 데이터 수에서는 데이터 밀도가 희박(Sparse)해지기 때문에 더 많은 데이터가 필요합니다.
차원 축소는 왜 하는 것일까?
여러가지 이유가 있겠지만 다음 네가지로 요약할 수 있습니다.
1. 비용, 시간, 자원, 용량 문제
- 불필요한 변수 저장 : 용량 문제 발생할 수 있음
- 차원이 많아지면 비례해서 분석시간 증가함
2. 차원이 높으면 과적합(Overfitting) 문제
- 변수가 많으면 복잡도 증가 ↑
- 민감도 증가 ↑ : 오차가 커질 수 있는 가능성 높아짐
3. 군집화 분석 결과가 좋지 않음
- 벡터(데이터 포인트) 간의 거리가 유사하게 되는 문제
4. 차원이 높으면 설명력이 떨어짐
- 저차원은 2~3개 속성으로 설명이 가능
- 3차원까지는 시각화가 가능
차원 축소 효과
차원을 축소하게 되면 변수간 상관성을 제거하여 결과의 통계적 유의성을 제고할 수 있습니다. 이것을 다중공선성이라고 합니다. 주요 정보를 보존한 상태에서 중복되거나 불필요한 정보만 제거합니다. 고차원의 정보를 저차원으로 축소하여 시각화(visualization) 가능해집니다.
차원 축소 방법
차원 축소 방법은 크게 두가지가 있습니다. 간단하게만 설명하고 더 자세한 내용은 아래 포스팅에서 다루도록 하겠습니다.
[머신러닝] Feature Selection 방법 - Filter, Wrapper, Embedded
이번 포스팅에서는 Feature Selection(차원 선택)에 대해 살펴 보겠습니다. 변수를 제거한다고 해서 Feature removal이라고도 합니다. 해당 도메인의 비즈니스를 잘 알면 분석가의 감으로 변수 선택도 가
bommbom.tistory.com
1. Feature Selection
통계적인 방법을 이용하여 feature들의 중요도에 순위(rank)를 정해 결정하는 방법입니다. 이 방법 또한 information loss(정보 손실)가 발생할 수 있습니다. 또 동일한 문제를 푸는 다른 데이터셋에서는 rank가 다르게 매길 수 있다는 문제가 있습니다. 단점은 선택되지 않는 feature가 가지고 있는 정보를 최종 분석에 사용하지 못합니다. 그래서 Feature Extraction이 필요한 이유입니다.
2. Feature Extraction
새로운 독립적인 feature를 만드는 방법으로 새로 만들어진 feature는 기존에 존재하였던 독립적인 feature들의 결합으로 생성합니다. 장점은 전체 feature이 가진 모든 정보를 사용할 수 있다는 점 입니다. 이 방법에는 linear한 방법과 non-linear한 방법들로 나뉘어집니다.
- Linear methods : 주성분 분석(PCA), FA, LDA, 특잇값 분해(Singular Value Decomposition, SVD)
- Non-linear methods : Kernel PCA, t-SNE(t-distributed Stochastic Neighbor Embedding), Isomap, Auto-encoder
'데이터 분석' 카테고리의 다른 글
| 차원축소 - 투영과 매니폴드(manifold) 학습은 어떻게 다른가? (0) | 2023.10.10 |
|---|---|
| [머신러닝] Feature Selection 방법 - Filter, Wrapper, Embedded (0) | 2023.10.06 |
| Boosting 알고리즘 - CatBoost 특징(Ordered Boosting, Target Encoding 장단점) (0) | 2023.10.05 |
| Boosting 알고리즘 - Light GBM 특징(GOSS, EFB, 장단점) (2) | 2023.10.04 |
| Boosting 알고리즘 - GBM(Gradient Boosting) 특징과 동작 원리 (0) | 2023.09.25 |



