『 '데이널'의 컨텐츠에 포함된 정보는? 』
XGBoost는 앙상블 부스팅 알고리즘 시리즈 중에 강력하다고 손꼽는 기법입니다. Light GBM(LGBM)이 나오기 전에는 XGBoost 만큼 성능 좋은 알고리즘이 찾기 힘들 정도였죠.
XGBoost의 특징을 알게되면 이전에 봤던 GBM과 어떻게 다른지를 명확하게 개념이 생길것입니다. 추가로 XGBoost의 동작 원리를 이해하고, 그 장단점까지 따져보로록 하겠습니다.
XGBoost 란?
XGBoost는 eXtreme Gradient Boosting의 약자입니다. 논문 XGBoost : A scalable Tree Boosting System에서 발표된 알고리즘으로 GBM(Gradient Boosting)과 다르게 병렬 학습이 지원되도록 구현한 라이브러리입니다. 생각해 보면 병렬이 지원된다는 것은 획기적인 발전입니다.
GPU는 딥러닝 알고리즘에서만 유효한 걸로 오해하시는 분들이 많은데요. XGBoost의 경우도 CPU보다는 GPU를 사용해야 합니다. 이유는 정확한 예측을 위해 수많은 결정 트리를 만들고 다양한 설정을 시도해야 하기 때문이죠.
이는 CPU로는 처리하기 어려운 방대한 양의 계산을 필요로 합니다. GPU는 동시에 여러 작업을 처리하는 데 특화되어 있어 XGBoost의 학습 속도를 비약적으로 빠르게 만들어줍니다. 저는 이 근거를 엔비디아 홈페이지에서 확인할 수 있었습니다.
XGBoost는 기본적으로 Regression, Classification 문제를 모두 지원하면서도 성능과 자원 효율 측면에서 좋습니다. 그런 이유로 분석가(Data scientist)들이 자주 사용하는 선호 알고리즘입니다. 분석 대회(Kaggle, DACON 등)에서 상위를 차지한 많은 참가자들이 XGBoost를 사용해서 좋은 성적을 냈으니 증명됐다고 봐조 좋을 것 같네요.
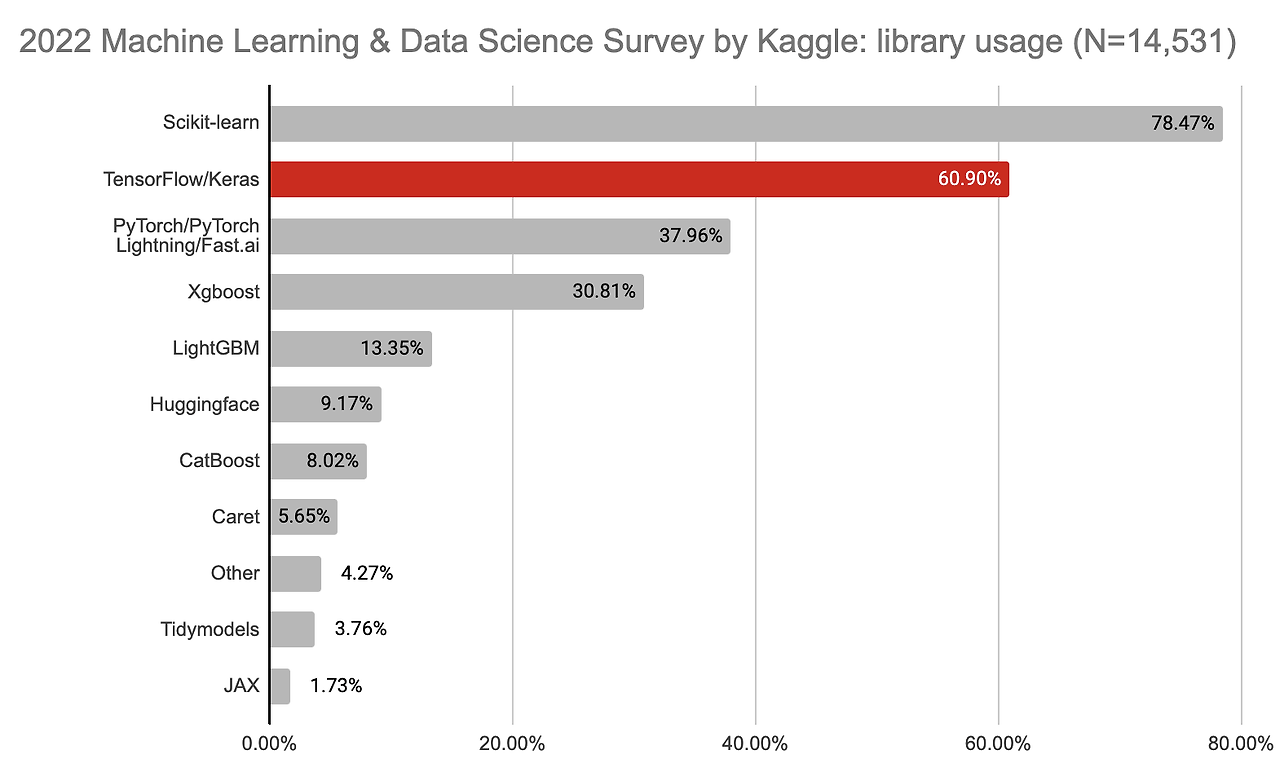
아래 2022년 통계에 의하면 기본적인 라이브러리 Scikit-learn과 두개의 딥러닝 라이브러리(TensorFlow, PyToch)를 다음으로 4위를 차지했네요. 이렇게 XGBoost는 입소문을 타고 널리 세상에 알려졌다고 볼 수 있습니다.
동작 원리(Approximate Algorithm)
- Step 1 : 정렬된 전체 데이터셋이 가진 영역(Global)을 몇 개의 영역(Local)으로 분할 합니다.
- Step 2 : 분할된 데이터셋(Bucket)들의 대해 별도 Split Point 찾습니다.
- Step 3 : 각 Bucket별 Gradient를 계산하여 Best Split Point(얻을 수 있는 정보량이 최대가 되는 지점)를 찾습니다.
- Step 4 : 각 Bucket별로 병렬처리가 가능합니다.

결론적으로 XGBoost는 Bucket별 병렬처리가 가능하기 때문에 전체 데이터 셋을 확인하는 Greedy Algorithm보다 효율적입니다. Greedy Algorithm은 대표 알고리즘으로 의사결정나무(Decision Tree)가 있습니다.
GBM vs XGBoost 비교 분석
1. 정규화(regularization) 측면
- XGBoost는 GBM 모델 대비해서 Overfitting(과대적합)이 더 잘 발생합니다. 그 과적합을 막기 위해 정규화에 더 신경써야 합니다.
2. 병렬처리 유무
- GBM은 순차적 수행을 해야 하기 때문에 병렬처리를 할 수 없지만, XGBoost는 병렬처리가 가능하다는 점이 다릅니다. 효율성을 위해 병렬처리 가능하게 만들었습니다.
3. 파라미터 및 설정 난의도
- GBM에 비해 XGBoost는 목적과 평가기준에 맞는 설정 가능하기 때문에 Highly Flexible 하다고 합니다. 그만큼 하이퍼파라미터 설정의 난의도는 높습니다.
4. Tree Pruning(가지치기) 방식
- GBM은 마이너스 Loss를 만나면 Stop 합니다. 일반적인 결정트리 가지치기라고 생각하면 됩니다. 하지만 XGBoost는 max_depth까지만 split 하고 positive gain 없는 노드 삭제하는 방식입니다.
만약, Gradient Boosting의 특징 및 동작원리를 알고 싶다면 링크를 참고하시기 바랍니다.
XGBoost 특징
1. Regularization과 가중치 지정
- XGBoost는 L1(Lasso) 및 L2(Ridge) 정규화와 가중치 지정 기능을 포함하고 있어, 모델의 복잡성을 제어하고 과적합을 방지하는 데 도움을 줍니다.
2. 자동적인 가지치기
- XGBoost는 트리의 성장 과정에서 가지치기를 수행하여 과적합을 방지하며, 최적의 트리 구조를 찾습니다.
3. 병렬 처리와 GPU 지원
- XGBoost는 병렬 처리를 지원하므로 대용량 데이터셋에서도 빠른 학습과 예측이 가능합니다. 또한, GPU를 활용하여 계산 속도를 향상시킬 수 있습니다.
4. 다양한 손실 함수 지원
- XGBoost는 분류와 회귀 문제에 대한 다양한 손실 함수(loss function)를 지원합니다. 예를 들어, 이진 분류에서는 로지스틱 손실 함수, 다중 분류에서는 소프트맥스 손실 함수 등을 사용할 수 있습니다.
5. 결측값 처리
- XGBoost는 결측값(missing values)을 처리하기 위한 특별한 처리 방식을 제공하며, 결측값을 자동으로 다룰 수 있습니다.
6. 특성 중요도 추정
- XGBoost는 각 특성의 중요도를 추정할 수 있으며, 어떤 특성이 예측에 가장 큰 영향을 미치는지 파악하는 데 도움을 줍니다.
XGBoost 파라미터 튜닝
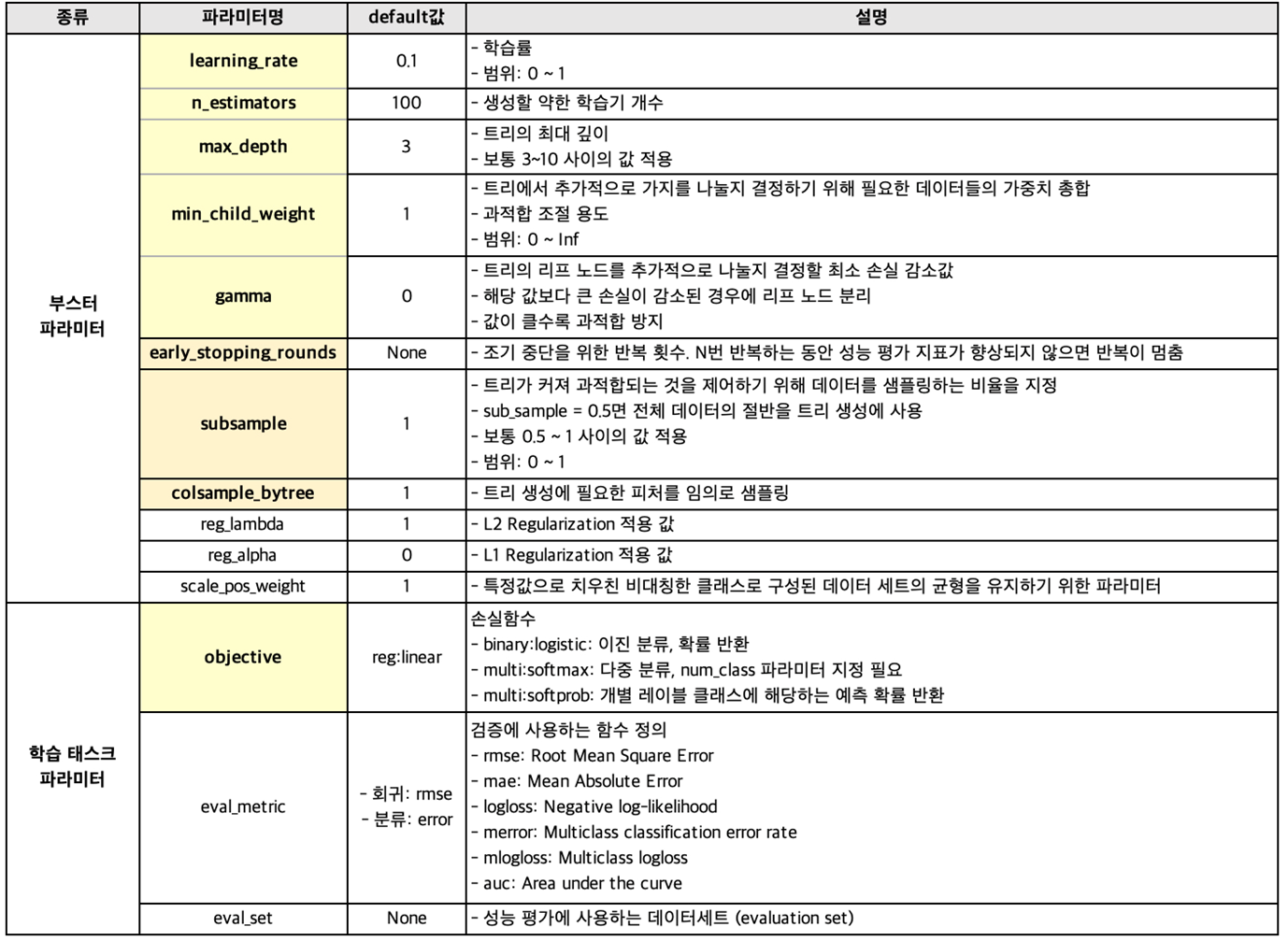
XGBoost는 병렬 처리 및 분류 성능을 좋게 하기 위해 하드웨어적인 부분까지 그것에 맞는 방식을 제공합니다. 또 기존 GBM을 기반으로 성능을 개선하려고 했습니다. 아래는 설정 가능한 XGBoost의 파라미터들입니다.
XGBoost 장단점
장점
- XGBoost는 샘플링 GBM 대비 빠른 수행시간을 보입니다. 이유는 병렬 처리로 학습하기 때문에 분류 속도가 빠릅니다.
- 표준 GBM 경우 과적합 규제기능이 없으나, XGBoost는 자체에 과적합 규제(Regularization) 기능으로 강한 내구성을 가집니다.
- 분류와 회귀영역 모두에서 뛰어난 예측 성능 발휘합니다.
- 파이썬 graphviz 패키지를 설치하면 CART(Classification and regression tree) 앙상블 모델로 손쉽게 사용할 수 있습니다.
- 과적합을 조절할 수 있는 Early Stopping(조기 종료) 기능이 있습니다.
- 다양한 옵션을 제공하며 Customizing이 용이합니다.
- 결측치(Missing Values)를 내부적으로 처리하는 기능이 있습니다.
- Tree모형을 기반으로 하기 때문에 복잡한 비선형문제를 빠른 시간에 풀 수 있습니다.
단점
- Tree 모델의 단점인 학습 데이터 내 값만 예측 가능합니다.
- 튜닝 할 때 손봐야 할 하이퍼파라미터가 많습니다. 분석가의 감과 실력에 의존되는 부분입니다.
- 데이터가 많으면 여전히 느린 속도를 냅니다.
- In-memory 방식이기 때문에 데이터가 메모리에 모두 올릴 수 없으면 탐색 불가합니다.
- 모든 경우 수를 다 탐색해야 하기 때문에 분산처리가 안됩니다. 여기서 분산은 병렬처리와 개념이 다릅니다.
마무리
XGBoost는 Kaggle과 같은 데이터 과학 대회에서 매우 인기 있는 알고리즘 중 하나이며, 실제 업무에서도 다양한 분야에서 활용되고 있습니다. 이 알고리즘은 예측 성능뿐만 아니라 모델 해석성(interpretability)과 효율성을 고려하는 머신 러닝 프로젝트에 매우 유용한 도구입니다.
실제로 XGBoost는 모델의 예측 결과를 해석하기 위한 다양한 도구와 시각화 기능을 제공하기 때문에 비즈니스 의사결정에 활용할 수 있습니다. 마지막으로 AdaBoost, GBM, XGBoost, LGBM, CatBoost 등 부스팅 알고리즘에 원리는 아래 글을 참고하시기 바랍니다.
Boosting 알고리즘(AdaBoost, GBM, XGBoost, LightGBM, CatBoost)
이번 포스팅은 부스팅 알고리즘에 대해 이야기 해보겠습니다. Boosting 알고리즘은 최근 Kaggle 대회에서 Deep Learning 다음으로 높은 수상 비중을 차지하고 있습니다. 그 이유는 우선 다른 모델보다
bommbom.tistory.com
'데이터 분석' 카테고리의 다른 글
| 데이터 전처리 첫걸음, 변수 속성 불일치 해결법 (0) | 2024.10.07 |
|---|---|
| 데이터 분석 실패 원인 1위? 바로 변수 명명과 정제 실수! (1) | 2024.10.04 |
| Data Imputation(데이터 대치, 결측치 처리) 및 흔한 실수들 (0) | 2024.04.30 |
| 가설 검정 왜 필요할까? t-test, ANOVA, 카이제곱 검정 (0) | 2024.04.29 |
| 통계학에서 정규분포가 중요한 이유 (0) | 2024.04.24 |



