이번 포스팅에서 딥러닝 모델의 일반화 방법들에 대해 알아보겠습니다. 성능 좋은 딥러닝 모델을 만들려고 하면 일반화 방법을 사용해야 하는데요. 여러 가지 일반화 기법들이 있습니다. 이 글에서 각 기법별로 특징과 어떤 경우에 사용하는지를 살펴보도록 하겠습니다.
왜 모델을 일반화할까?
모델을 학습하다보면 Training 데이터만 잘 맞추고 새로운 데이터에 대해 정확하게 예측하지 못하는 경우가 생깁니다. 이 현상을 과대적합(Overfitting)이 발생했다고 하죠. 모델이 다양한 실제 상황에서 잘 수행되게 만드는 과정이 일반화 과정이라고 합니다. 아래에서 소개하는 기법들을 통해 학습을 개선하게 됩니다.
데이터셋 큐레이션(의미부여 재창출)
'쓰레기가 들어오면 쓰레기가 나온다'는 말처럼 우선 데이터에 집중해서 생각해 볼 수 있습니다. 데이터셋에 노이즈가 많거나 불연속 한 경우 딥러닝 학습에 악영향을 미칩니다. 딥러닝은 일종의 분포 곡선을 맞추는 작업이기 때문입니다. 아래 질문들을 이용해 데이터를 점검하고 조치해야 합니다.
- 데이터가 충분하게 확보되었나? → 오버샘플링, 데이터 증대(data augmentation)
- 입력에서 출력을 매핑하는 공간이 조밀하게 샘플링 되었나? → 임밸런스 문제 해결
- 데이터를 시각화하여 이상치가 있는가? → 이상치 확인 후 레이블 교정
- 데이터 전처리는 잘 되었나? → 데이터를 정제하고 누락 값을 imputation
- 특성(feature)이 너무 많지는 않은가? → feature selection(유용하지 않는 feature 제외)
특성공학
최근 딥러닝에서 feature seletion과 같은 특성공학이 필요치 않다고 이야기합니다. 그 이유는 신경망에서 자동으로 원본 데이터에서 유용한 특성을 추출하는 과정을 거치기 때문이죠. 하지만 좋은 특성(feature)을 선택하는 것은 적은 자원을 사용하여 더 잘 문제를 풀 수 있게 해 줍니다. 다른 측면으로 데이터가 양이 많이 확보되지 않았을 때도 좋은 모델을 만들 수 있다는 것입니다. 결론적으로 리소스와 속도, 정확도를 향상해 줍니다.
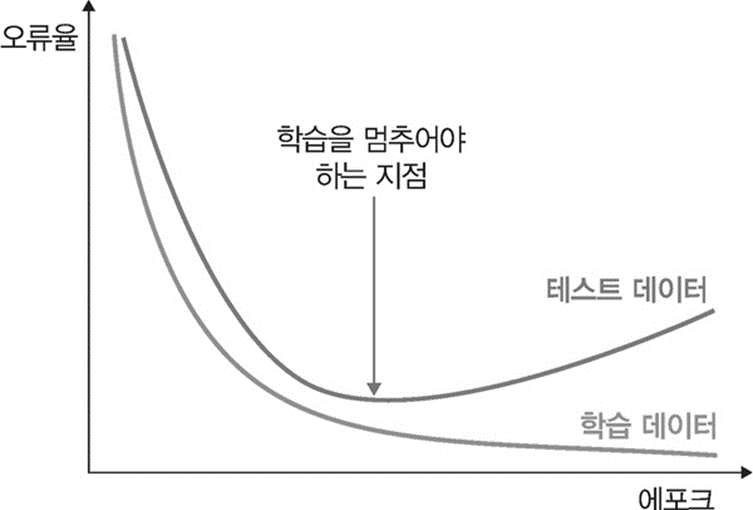
조기종료(Early Stopping)
모델을 끝까지 훈련하면 과대접합이 발생하기 때문에 훈련 손실이 최소값에 도달하기 전에 훈련을 중단하는 기법을 말합니다. 파이썬 프로그램에서는 EarlyStopping옵션을 설정하면 자동으로 학습을 조기 종료합니다. 이 원리는 가장 적합한 epoch 횟수를 찾는 것입니다. epoch가 끝날 때마다 모델을 저장하고 최선의 epoch를 찾은 후 저장된 모델을 재사용하는 방법 사용합니다.
- 최적적합 지점 : 과소적합과 과대적합 사이의 경계
모델 규제(regularization)
이 기법은 모델을 더 간단하고 단순하게 만드는 방법입니다. 시각화되는 곡선을 부드럽고 일반적이게 만드는 것을 모델 규제라고 하죠. 신경망에서는 알맞은 층의 수나 각 층의 노드 개수를 결정할 수 있는 공식은 따로 없습니다. 알맞은 모델을 찾기 위해서는 아래 작업을 수행해야 합니다.
- 먼저 적은 수의 층과 파라미터로 시작
- 검증 손실이 감소되기 시작할 때 층이나 유닛 개수를 늘림
가중치 규제 추가
과대적합을 완화하기 위해 모델의 복잡도에 제한을 두는 방법 중에 가중치가 작은 값을 가지도록 강제할 수 있습니다. 가중치가 결국 과적합을 만들기 때문이죠. 이렇게 하면 가중치 값의 분포가 균일하게 되는데 이를 가중치 규제라고 합니다.
L1 규제 : 랏소
- 가중치의 절대값에 비례하여 비용이 추가됨
- 규제가 커질 수록 가중치 값이 0이 됨
L2 규제 : 릿지
- 가중치의 제곱에 비례하여 비용이 추가됨
- 규제가 커질 수록 영향도 감소
L2 규제는 신경망에서 가중치 감쇠(weight decay)로 부릅니다. 가중치 규제는 보통 작은 딥러닝 모델에 사용하는 게 일반적입니다. 대규모 딥러닝 모델은 파라미터가 너무 많아 가중치 값을 제약하는 것이 모델 일반화에 큰 영향을 미치지 못하기 때문이죠. 이런 경우는 드룹아웃을 더 선호합니다.
드롭아웃 추가
드롭아웃은 토론토 대학의 '제프리 힌트'와 학생들이 개발했습니다. 모델 층에 무작위로 층의 출력 특성을 일부 제외하는 기법입니다. 해당 노드를 0으로 만드는 것이죠. 핵심 아이디어는 층의 출력 값에 노이즈를 추가하여 '중요하지 않은 우연한 패턴을 깨뜨리자'는 것이었습니다. 이상 패턴에 잘 견디는 더 견고한 모델이 만들어지게 됩니다.
전이 학습
관련 작업을 위해 대규모 데이터셋에서 사전 훈련된 모델을 활용하는 방법도 있습니다. 기 학습된 모델에 특정 문제에 대해 미세 조정하면 일반화가 개선되는 경우가 많습니다. 전이 학습을 통해 모델은 한 도메인에서 얻은 지식을 활용하고 이를 다른 도메인에 효과적으로 적용할 수 있습니다.
결론
딥러닝 모델에서 일반화 꼭 고려해야 하는 단계입니다. 일반화에 영향을 미치는 요인을 이해하고 훈련 과정에서 효과적인 기법을 사용해야 합니다.
'딥러닝' 카테고리의 다른 글
| 오차역전파 알고리즘: ReLU, Sigmoid, Affine, Softmax 계산 (0) | 2024.01.26 |
|---|---|
| 오차역전파 알고리즘: 핵심은 연쇄법칙(chain rule) (0) | 2024.01.25 |
| 딥러닝 하이퍼파라미터 튜닝 및 설정 (0) | 2024.01.23 |
| 딥러닝의 수치미분과 편미분: 꼭 알아야 할 미분 공식 (1) | 2024.01.22 |
| 딥러닝 학습 방법: batch size, Iteration, epoch(에포크) (0) | 2024.01.19 |



