이번 포스팅은 불균형 데이터 처리 방법 중에 오버 샘플링에 대해 살펴보겠습니다. Over Sampling은 Imbalance 데이터를 처리할 때 가장 많이 사용하는 방법입니다.
오버 샘플링(Over sampling)
소스 클래스의 샘플을 증가시켜 소수 클래스와 다수 클래스 크기를 동일하게 만드는 기법입니다. 일반적으로 오버 샘플링을 했을 때 대체적으로 효과가 있습니다. 하지만 램던 오버샘플링(소수 샘플 복제)은 동일한 정보를 복사하기 때문에 오버피팅을 유발할 수 있으니 주위해야 합니다.
Resampling
Resampling은 소수 범주의 데이터를 단순히 복제하여 데이터의 수를 늘리는 방법입니다. 아래 그림에서 확인 할 수 있듯이 부정(-) 클래스에 동일한 위치에 건수만 증가하는 방식입니다. 보시다시피 단순 복제하는 방식으로 새로운 데이터를 생성하는 것은 아니며 분류 경계면을 결정할 때 소수 클래스에 대한 가중치가 증가합니다. 이로 인해 좀 더 경계면이 뚜렷해져 성능 향상에 도움이 됩니다. 단점은 소수 범주의 데이터 세트가 전체 모집단을 대표한다는 보장이 없습니다. 그래서 소수 범주에 과적합이 발생할 가능성이 있습니다.
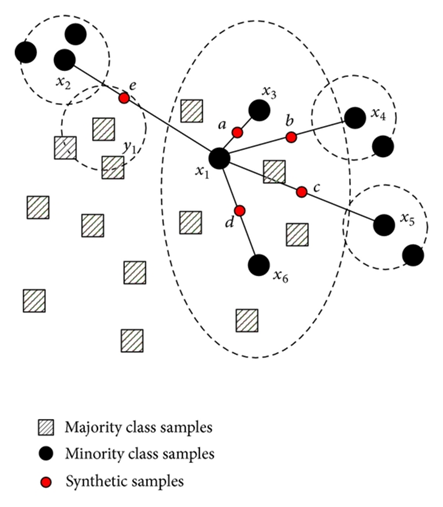
SMOTE(Synthetic Minority Oversampling TEchnique)
SMOTE는 Synthetic Minority Oversampling TEchnique의 약자로 '스므트'라고 읽습니다. 임의의 소수 클래스 데이터 사이에 새로운 데이터 생성 방법입니다.
동작 방식
- 소수 클래스의 데이터 중 특정 벡터(샘플)와 가장 가까운 k개의 이웃 벡터를 선정함(K-NN 알고리즘 방식과 동일)
- 기준 벡터와 선정한 벡터 사이를 선분으로 연결
- 선분 위의 임의의 점이 새로운 벡터(혹은 이 중 임의의 하나)를 생성
데이터 중 하나를 랜덤으로 선정해 Synthetic 공식을 통해 가상의 데이터를 계산하는 방식입니다. 단순 무작위 방법보다는 과적합 적은 장점이 있습니다. 단, K값은 2이상의 정수값이어야 합니다.
Borderline - SMOTE
보더라인 스므드는 용어처럼 Borderline 부분에 대해서만 SMOTE 방식을 사용하는 기법입니다. 이렇게 한 이유는 경계부분은 특히 오버 샘플링하는 것이 도움이 된다는 아이디어였습니다.
동작 방식
- 우선은 보더라인을 찾는다.
- 소수 클래스에 속하는 데이터 하나를 선정해 N개 주변을 탐색한 후 이 N개 데이터 중 다수 클래스에 속하는 데이터가 몇개인지 확인한다.
- 이 때 다수 클래스에 속하는 개수 K에 따라 보더라인 인지 여부를 결정하며 그 데이터가 Safe 관측치인지, Danger 관측치인지, Noise 관측치인지 결정한다.
결정 방법
- k/2 < k' < k : Danger 관측치 -> 보더라인(반 초과, 전체 아님)
- 0 =< k' =< k/2 : Safe 관측치 -> 다수가 반 이하
- k = k' : Noise 관측치 -> 전체가 다수
ADASYN(에이다신)
에이다신은 Borderline-SMOTE와 비슷한 방식이지만 샘플링 개수를 데이터 위치에 따라 다르게 설정한다는 것이 차이점입니다.
동작 방식
- 먼저 모든 소수 클래스 데이터에 각각에 대해 주변 데이터 K개수 만큼 탐색하고 그 중 다수 클래스 관측치의 비율을 계산
- 정의된 공식에 의해 스케일링한 Ri값들 이용하여 각 데이터에서 SMOTE 방식을 이용해 오버샘플링
- 소수 클래스 주변의 다수 클래스 수에 따라 유동적으로 오버샘플링 할 데이터 개수를 생성
Borderline-SMOTE의 보더라인에 집중한다는 점과 동시에 다수 클래스 데이터 주변에 존재하는 소수 클래스에 집중한다는 두가지 장점을 모두 가지고 있습니다.
Over Sampling의 장단점
- 장점
- 정보 손실이 없음
- 대부분의 경우 언더 샘플링에 비해 높은 분류 정확도를 보임
- 단점
- 과적합 가능성
- 데이터가 늘어나서 계산 시간이 증가
- 노이즈 또는 이상치에 민감
마무리
왜 클래스가 불균형한지 그 이유를 이해하고 적절한 오버샘플링 전략을 선택하는 것이 관건입니다. Over Sampling은 모든 상황에서 효과적인 해결책이 아닐 수도 있습니다. 오버샘플링은 하나의 전략 중 하나일 뿐입니다. 상황에 따라 적절한 전략을 선택하고 신중하게 조정하여 모델의 성능을 향상시키는 것이 중요합니다. 다음 포스팅에서는 불균형 데이터의 또하나의 방법인 Under Sampling에 대해서도 알아보도록 하겠습니다.
'데이터 분석' 카테고리의 다른 글
| 나이브 베이즈(Naive Bayes) - 확률적 생성 모델, Likelihood (1) | 2023.10.23 |
|---|---|
| 불균형 데이터(Data Imbalance) 처리 - 모델 조정 방법(Cost-Sensitive,Focal loss,Novelty Detection (0) | 2023.10.23 |
| 불균형 데이터(Data Imbalance) 처리 - 언더 샘플링(Under Sampling),Tomek Links,CNN,OSS (2) | 2023.10.21 |
| 불균형 데이터(Data Imbalance) 처리 및 해결 방법(2가지 측면) (0) | 2023.10.20 |
| 분류 모델 성능 평가 - Confusion Matrix 쉬운 설명, threshold, cut-off (0) | 2023.10.20 |



