데이터 분석을 하다 보면 한가지 문제에 봉착하게 됩니다. 바로 과적합에 대한 문제입니다. 이번 포스팅에서는 과대적합과 과소적합에 대해서 알아보도록 하겠습니다.
Underfitting(과소적합)
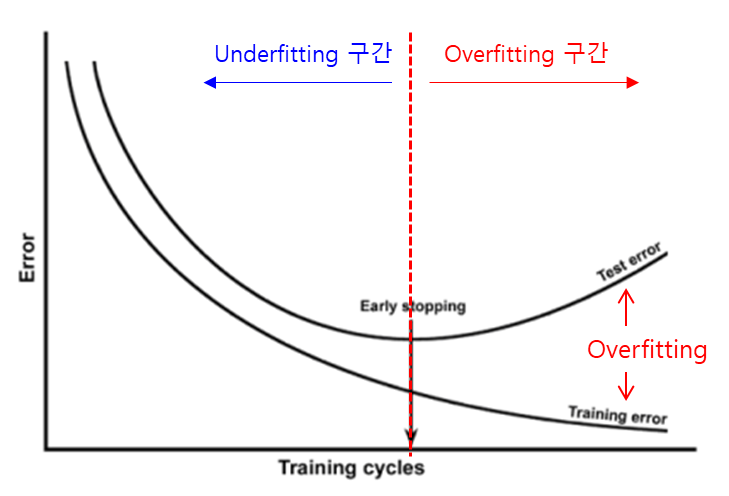
먼저 생각해 볼 부분이 왜 Underfitting은 발생하는 걸까요? 대체적으로 Underfitting(과소적합)은 모델이 너무 단순하기 때문에 생깁니다. 우리가 분석하고자 하는 데이터의 내재된 구조를 제대로 학습하지 못할 때 발생하게 됩니다. Underfitting을 알 수 있는 방법은 학습 데이터 오류율이 테스트 데이터 오류율 비슷하게 나오지만 오류율이 여전히 큰 경우는 Underfitting을 의심해 봐야 합니다.
그렇다면 어떻게 Underfitting 해소할 수 있을까요? 모델이 데이터를 담아내기에 충분치 않기 때문에 파라미터가 더 많은 복잡한 모델을 다시 만드는 것이 방법입니다. 또 한가지는 모델의 제약들을 줄이는 방법입니다. 모델의 제약을 늘리면 그 제약 때문에 일반화된 모델 즉, 단순한 모델이 됩니다. 그리고 아직 학습이 덜 된 경우일 수 있으니 조기종료 시점까지 충분이 학습하는 것이 좋습니다. 일반적으로 분석 방법으로 Overfitting 전 시점까지 학습을 해야 최적의 지점을 찾을 수 있습니다.
Overfitting(과대적합, 과적합)
Overfitting(과대적합) 원인은 무엇일까요? 과적합은 매개변수가 많고 표현력이 높은 모델 즉, 복잡한 모델에서 자주 발생됩니다. 또는 훈련 데이터 적을 때 발생하기도 합니다. 이는 충분한 데이터 확보가 되지 않았기 때문에 모델이 잘 학습되지 않기 때문입니다. Overfitting이 발생하는 이유는 학습 데이터에 대해 과도하게 학습해서 입니다. 너무 학습 데이터에 최적화되어 있기 때문에 실제 데이터에 대한 오차가 증가하는 현상이 생깁니다.
학습 데이터 오류율이 테스트 데이터 오류율보다 현저하게 클 경우 Overfitting을 의심할 수 있습니다. (학습 정확도 >> 검증 정확도) 예를 들어, 훈련 정확도 99%, 검증 정확도 80%로 두 정확도 사이의 격차가 19%나 난다면 문제가 있는 것입니다. 이 현상을 해석해 보면 모델이 훈련 데이터에 특화된 패턴을 학습하기 시작했다는 의미입니다. 해당 패턴은 새로운 데이터에 대해 잘못된 판단 가능성이 높아집니다.
어떻게 하면 Overfitting을 해소할 수 있을까요? 일반적인 방법으로는 데이터 수를 늘려야 합니다. 충분히 학습이 이루어지지 않아서 발생하는 문제 해결하는 방법입니다. 그 다음은 모델의 복잡도 줄여야 합니다. Overfitting이 됐다는 것은 훈련 데이터에 너무 fit한 모델로 복도가 증가했다는 것이므로 모델을 일반화할 필요가 있습니다. 모델을 일반화하는 방법으로는 가중치 감소, 정규화(Regularization) 등 여러가지 방법이 있습니다.
일반화, 데이터 작업
일반적으로 모델이 새로운 데이터에 대해 정확히 예측할 수 있으면 훈련 데이터에서 테스트 데이터로 '일반화'되었다고 말합니다. 우리가 모델을 말들 때 근본적인 이슈는 최적화와 일반화 사이의 줄다리기를 하는 것입니다. 우리가 생각해 봐야 할 점은 과대적합이 나쁜 것만은 아니라는 것입니다. 우리는 과대적합과 과소적합의 경계에 있는 이상적인 모델을 만들기를 원합니다. 그렇기 하기 위해서 그 위치가 어디 있는지 알기 위해 과대적합까지 모델을 만들어 보아야 알기 때문입니다.
좋은 모델을 만들기 위해 탐색적 분석(EDA)을 다시 해보는 것도 필요합니다. 변수들의 중요한 기초 통계(평균, 표준편차, 중앙값 등) 찾아보고 집단 별 통계도 확인해야 합니다. 머신 러닝에 학습하게 될 패턴 파악하는 것이 중요하기 때문입니다. 가짜 상관관계 특성(feature) 찾아 제거하는 것도 생각해 볼 수 있습니다. 예를 들어, 고양이의 성격에는 털의 색깔이 관련이 없는데, 색깔에 상관도가 높은 모델은 과대적합이 발생합니다. 집단 별 통계인 bar chart 부터 전체 분산 정도를 확인할 수 있는 Scatter plot(산점도) 시각화 해서 분석하는 것이 좋습니다.
수집 샘플 데이터의 적절성도 점검이 필요합니다. 머신러닝 모델을 적용하고자 하는 모든 집단으로부터 골고루 수집된 데이터인지 확인 해야 합니다. 수집된 데이터가 특정 집단에 한정되면 모델이 보편적으로 적용할 수 없습니다. 그런 경우는 일반화된 모델이 만들어지지 않습니다. 그래서 다양한 데이터 포인트를 수집해야 실제 데이터를 예측하는 성능이 좋아진다고 할 수 있습니다. 비슷한 데이터를 모으는 것은 모델 성능에 도움이 되지 않습니다. 이런 이유로 원자료에 대한 기초 통계나 산점도 시각화를 통해 더 많은 샘플을 확보하는 노력이 필요합니다.
데이터를 추가하거나 삭제할 때도 고려할 점이 있습니다. 훈련 데이터를 추가로 획득하는 것이 중요한 이유는 앞에서 말한 것처럼 데이터의 편향을 줄일 수 있습니다. 예를 들어, 2건의 정답이 있는 훈련 데이터의 경우 과적합 확률이 높기 때문입니다. 훈련 데이터 노이즈 제거, 오류 수정, 이상치 제거 등을 줄이는 작업이 정확도에 큰 영향을 줍니다.
결론적으로, 과적합과 과소적합 사이의 미묘한 균형을 찾는 것은 기계 학습의 핵심 과제입니다. 일반화가 잘되고 과적합과 과소적합의 위험을 피하는 모델을 만들려면 사려 깊은 데이터 분석, 모델 선택, 데이터 전처리의 조합이 필요합니다.
'데이터 분석' 카테고리의 다른 글
| [머신러닝] 과적합(Overfitting) 해소 방법 - 정규화 (3) | 2023.09.08 |
|---|---|
| [머신러닝] 과적합(Overfitting) 해소 방법 - 모델 단순화 (0) | 2023.09.07 |
| [머신러닝] 데이터 전처리 - 변수 결합 (0) | 2023.09.05 |
| [머신러닝] 데이터 전처리 - 변수 추가/제거 (0) | 2023.09.04 |
| 데이터 전처리 필수 단계: 결측치 처리 방법 비교 분석 (2) | 2023.09.01 |



