지금까지는 내부에 있는 데이터를 이용하여 데이터를 전처리 했다면 이번에는 외부 데이터까지 연결하는 작업입니다. 데이터의 속성은 예측을 위해 더 많은 정보가 있을 수록 유리합니다. 그렇기 때문에 공공 데이터 포털과 같은 외부 데이터와의 결합도 분석가는 고려해야 합니다.
1. Mashup의 필요성
수집한 원자료 이외 외부 데이터와 연결해서 분석하여 더 넓은 관점에서 Insight를 찾아는 방법입니다. 예를 들어, 공공데이터 포털에서 제공 다양한 행정, 날씨 등의 데이터들이 있습니다. 다양한 아이디어를 통해 외부 데이터와 결합했을 때 더 좋은 알고리즘 및 서비스를 만들 수 있습니다.
분석가가 예측하려는 Y(타겟) 변수와 연관이 있어 영향력이 있을 것으로 판단되는 데이터를 결합하는 방법입니다. 단, 외부 데이터는 아쉽게도 대부분 비식별화 처리 되거나 통계 값으로 존재 합니다. 가장 많이 결합하는 데이터는 성별, 연령대, 지역(행정동, 법정동, 구 등) 데이터 입니다.
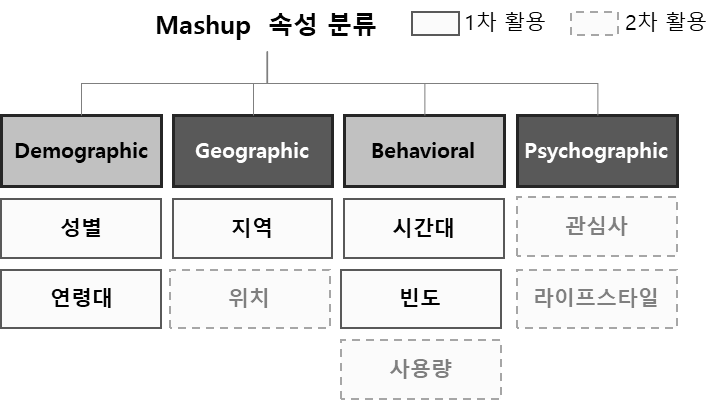
2. 데이터 연결
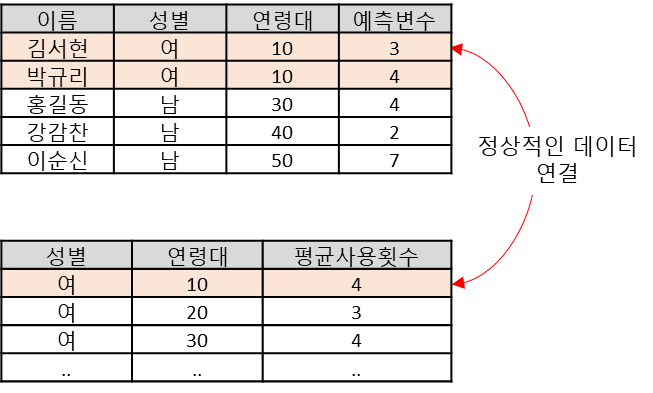
데이터 연결은 일반적으로 조인(join)이라는 방식으로 합니다. 데이터 결합 작업 순서는 첫번째, 데이터 생성 단위(Level) 확인 해야 합니다. 동일한 데이터 Level이여지 결합이 정상적으로 되기 때문입니다. 다음은 연결할 수 있는 변수 확인 해야 합니다. 데이터베이스로 말하면 조인 속성을 찾아야 합니다. 여기까지 진행됬으면 조인 속성을 통해 데이터는 결합할 수 있습니다. 결합 시 다음 두가지 방식으로 결합하게 됩니다.
1 : N 인 경우
1 : N 인 경우는 한쪽은 다른 한쪽 보다 더 상세한 경우 입니다. 이럴 경우는 일반화에 맞출 것인지, 세분화에 맞출 것인지 결정해야 합니다. 먼저 세분화된 레벨(N)에 맞출 경우는 1 쪽에 정보가 기여도가 떨어집니다. 왜냐하면 세분화 만큼 동일한 데이터가 들어가기 때문입니다. 반대로 일반화된 레벨(1)에 맞출 경우는 N 쪽 정보가 소실 됩니다. 이유는 Grouping된 통계 정보로 연결할 수 밖에는 없기 때문입니다.
N : M 인 경우
N : M 인 경우는 양쪽다 레벨이 다른 경우 입니다. 이럴 경우는 어느 한쪽 레벨에 맞춰서 결합행 합니다. 만약 레벨을 맞추지 않고 그대로 결합하면 잘못된 데이터가 대량 생성됩니다. 이 것은 초보 분석가가 자주 실수하는 오류 입니다. 결과적으로 예측 성능과 수행 성능이 하락하게 됩니다. 이유는 Cartesian Product(카티션 곱)이라는 의미 없는 데이타가 양산 되기 때문입니다. 이렇게 생기는 데이터는 Up Sampling과는 다른 결과 입니다. 전혀 일관성 없는 데이터가 추가로 생기기 때문에 정확도를 떨어뜨리는 원인이 됩니다.
3. 전처리 중요성
이렇게 전처리 작업을 전체적으로 살표 보았습니다. 전처리는 애정을 가지고 최선을 다해 해야 한다고 생각합니다. 정말 데이터를 정련, 재련한다는 느낌으로 해야 합니다. 거의 데이터 분석의 70~80% 해당하는 작업량이니 그만큼 많은 시간을 투자해야 하는 작업입니다. 분석가가 인사이트를 찾아내기 위한 노력, 근성 필요한 부분입니다. 결론적으로 내가 추론하는 모델에 가장 적합한 Input 데이터를 만드는 과정이기 때문에 중요하다고 할 수 있습니다.
'데이터 분석' 카테고리의 다른 글
| [머신러닝] 과적합(Overfitting) 해소 방법 - 모델 단순화 (0) | 2023.09.07 |
|---|---|
| [머신러닝] 과대적합 vs 과소적합(overfitting, underfitting) (0) | 2023.09.06 |
| [머신러닝] 데이터 전처리 - 변수 추가/제거 (0) | 2023.09.04 |
| 데이터 전처리 필수 단계: 결측치 처리 방법 비교 분석 (2) | 2023.09.01 |
| [머신러닝] 데이터 전처리 - 실수를 줄이는 데이터 확인 (0) | 2023.08.28 |



