랜덤 포레스트(random forest)에서 특성 중요도를 쉽게 측정할 수가 있는데요. 어떤 특징 때문에 가능한 것일가요? 그리고 장단점은 무엇인지 알아보도록 하겠습니다. 만약 Random Forest의 동작 원리에 대해 글을 읽지 않으셨다면 링크의 글을 읽어 보시는 것을 추천드립니다.
특성 중요도
랜덤 포레스트는 작은 트리들(trees)을 이용하는 방법을 사용해 특성의 상대적 중요도를 측정하기 쉽다는 특징이 있습니다. 랜덤 포레스트 특성 중요도는 Decision Tree 보다 더 신뢰할 만합니다. 이유는 여러 Tree를 통해 일반화 했기 때문이죠.
평균적인 불순도가 얼마나 감소하는지를 확인해 특성 중요도를 측정 가능합니다. 더 정확히 말하면 각 노드(node)의 속한 샘플의 가중치 평균이라고 계산한다고 생각하면 됩니다.
사이킷런은 훈련이 끝난 후 전체 feature의 중요도 합이 1이 되도록 정규화해서 결과를 저장합니다. 그 값은 feature_importances_ 변수에 저장됩니다. 결론적으로 랜덤 포레스트에서 feature selection을 해야 한다면 중요도를 이용하여 선택이 가능하다는 말입니다.
엑스트라 트리
랜덤 포레스트의 트리를 만들 때 무작위하게 만들기 위해 트리의 최적 임계값을 찾는 대신 feature를 무작위로 분할하여 최상의 분할을 선택하는 방식을 사용합니다. 이때 랜덤하게 뽑아진 결정트리를 estimator라고 합니다. 비슷한 트리만 생성되면 다양하지 않아 랜덤 포레스트 장점을 살릴 수가 없습니다. '익스트림 랜덤 트리'라는 용어는 극단적인 무작위 한 트리의 랜덤 포레스트를 말합니다. 이것은 앙상블 또는 '엑스트라 트리'라고도 불립니다. 일반적인 랜덤 포레스트보다 엑스트라 트리가 속도는 훨씬 빠릅니다.
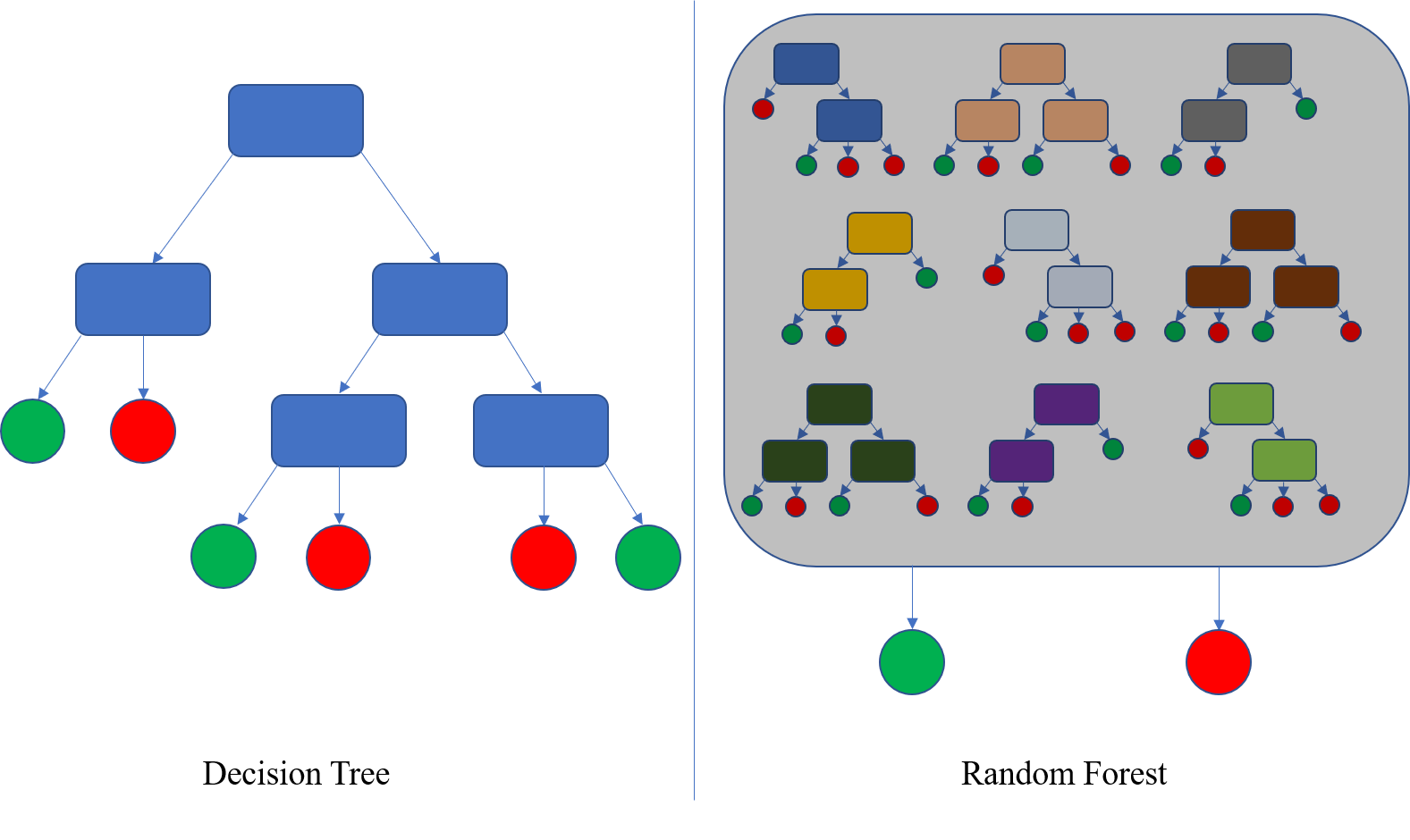
Random Forest의 특징 4가지
- 임의성 : 서로 조금씩 다른 특성의 트리들로 구성합니다. random이라는 용어에서 알 수 있습니다.
- 비상관화 : 각 트리들의 예측이 서로 연관되지 않습니다. 각각이 독립적입니다.
- 견고성 : 오류가 전파되지 않아 노이즈에 강합니다. decision tree처럼 하나의 트리가 아니기 때문에 가능합니다.
- 일반화 : 임의화된 모델을 여러개 가져가는 방식으로 일반화하여 과적합 문제 극복할 수 있습니다.
장점
- 랜덤 포레스트는 Classification(분류) 및 Regression(회귀) 문제에 모두 사용 가능합니다.
- Missing value(결측치)를 다루기 쉽습니다.
- 대용량 데이터 처리에 효과적입니다.
- 모델의 Overfitting(오버피팅) 문제를 회피하여, 모델 정확도를 향상시킵니다. 분류를 집계하는 방식으로 일반화하기 때문에 가지치기가 필요 없습니다.
- Classification 모델에서 상대적으로 중요한 변수를 선정 및 Ranking을 구하는 것이 가능합니다.
- 하이퍼파라미터 튜닝을 많이 하지 않아도 잘 작동합니다.
- 데이터 전처리에서 스케일링(scaling) 단계가 필요 없습니다.
- 단일 트리의 단점을 보완하고 장점은 그대로 가지고 있습니다.
단점
- 알고리즘에서 수백 또는 수천 개 트리를 만들기 때문에 분석 프로세스 속도가 느려집니다. 많은 메모리를 사용하여 작업을 한다고 볼 수 있습니다.
- 속도 측면에서 실시간 예측에는 비효율적입니다.
- 단, OOB(Out-of-bag) 샘플링을 통해 보완을 하고 있습니다. 이 샘플링에서는 데이터의 2/3만 예측에 사용합니다. 랜덤 포레스트 프로세스도 병렬화할 수 있어 프로세스를 여러 시스템으로 분할이 가능합니다. 그렇게 하면 단일 시스템에서보다 상대적으로 더 빠른 시간에 수행할 수 있습니다.
- 랜덤 포레스트는 앙상블이라 해석이 어렵습니다. 블랙박스와 같이 시각화해서 설명하지 못합니다.
- 텍스트 데이터 같이 매우 차원이 높고 희소한 데이터에는 잘 작동하지 않습니다. Random Forest보다는 선형 모델 또는 신경망이 더 적합합니다.
활용 분야
Random Forest는 데이터의 복잡성과 다양성을 다루는 데 효과적이면서 예측 성능이 뛰어나기 때문에 다양한 비즈니스 응용 분야에서 활용되고 있습니다.
- 신용 스코어링 : Random Forest를 사용하여 대출 신청자의 신용 위험을 예측하고 신용 스코어를 계산하는데 사용합니다. 이를 통해 금융 기관은 대출 승인 또는 거부 결정을 내릴 때 판단할 수 있는 정보로 활용할 수 있습니다.
- 질병 예측 : 환자 데이터를 기반으로 랜덤 포레스트 모델을 훈련하여 특정 질병의 발병 가능성을 예측해 줍니다. 의료 전문가는 조기 진단과 예방 조치를 취할 수 있습니다.
- 제품 품질 향상: Random Forest 모델은 제조 공정 데이터를 분석하여 제품 불량 발생 원인을 예측하고 품질 향상을 위한 조치를 제안해 주는 데 사용합니다.
- 보험 청구 사기 탐지: Random Forest 모델은 보험 청구 데이터를 분석하여 사기성 청구를 탐지하는 데 사용됩니다. 비정상적인 패턴을 식별하고 부정한 보험 청구를 방지합니다.
- 주식 시장 예측: 금융 데이터와 주식 시장 지표를 기반으로 Random Forest 모델을 사용하여 주식 가격의 추세를 예측합니다. 투자자와 투자 기관은 투자 결정을 지원하는 데 활용할 수 있습니다.
'데이터 분석' 카테고리의 다른 글
| Boosting 알고리즘 - Adaboost 동작 원리 (0) | 2023.09.24 |
|---|---|
| Boosting 알고리즘(AdaBoost, GBM, XGBoost, LightGBM, CatBoost) (0) | 2023.09.23 |
| 랜덤 포레스트(Random Forest) 동작 원리 및 OOB, Random Subspace (0) | 2023.09.21 |
| 랜덤 포레스트(Random Forest) 특징 - 앙상블 (0) | 2023.09.20 |
| 의사결정나무(Decision Tree) 종류 및 학습 - 장단점 (0) | 2023.09.19 |



