이번 글에서는 랜덤 포레스트 알고리즘에 대해 알아보도록 하겠습니다. Random Forest는 앙상블 모델로 Decision Tree의 문제점을 보완하기 위해 나왔습니다.
Decision Tree의 문제점은 훈련 데이터에 대해 과대적합(Overfitting) 되는 경향이 있었습니다. 데이터가 갖는 high variance 문제가 있을 때 발생하게 됩니다. 훈련 데이터에 민감한 것도 문제입니다.
계층적 구조로 인해 중간에 에러가 발생하면 다음 단계로 에러 전파 됩니다. 결국 학습 데이터의 미세한 변동에도 최종 결과에 크게 영향을 받게 됩니다. 결론적으로 일반화 과정이 필요하게 되며, Decision Tree 묶음이 바로 Random Forest입니다.
『 '데이널'의 컨텐츠에 포함된 정보는? 』
Random Forest의 특징
Random Forest 알고리즘은 왜 일반화가 될까요? 다수의 Tree를 기반으로 예측하기 때문에 그 영향력이 줄어들어 일반화된 정확도를 얻을 수 있습니다. Tree 모델의 예측 성능이 유지되면서 overfitting 줄어드는 것을 수학적 증명한 자료가 있습니다.(파이썬 라이브러리를 활용한 머신러닝, 116 page 참고)
‘무작위 숲'이라는 이름처럼 여러 개의 랭덤한 Tree모델을 생성하여 결과를 취합하여 결론을 만듭니다. 집단지성, 인기투표를 생각하면 이해가 쉽습니다. 의사결정나무 모델 여러 개를 훈련시켜서 그 결과를 종합해 예측하는 앙상블 알고리즘입니다. 의사결정나무 모델을 훈련시킬 때 앙상블 기법의 하나인 배깅(Bagging) 방식을 사용합니다.
앙상블
앙상블은 여러 Base모델의 예측을 다수결 법칙 또는 평균을 이용하여 통합하여 예측의 정확도를 향상시키는 방법을 말합니다. 대중의 지혜(wisdom of the crowd)를 이용하는 것입니다. 일련의 예측기(분류 나 회귀)로부터 예측을 수집하면 가장 좋은 모델 하나보다 더 좋은 예측을 얻을 수가 있습니다. 성능이 약한 학습기(weak learner)를 여러 개 연결하여 순차적으로 학습함으로써 강한 학습기(strong learner)를 만드는 것이 앙상블 학습 기법입니다.
앙상블의 요건은 개별 모델이 서로 독립적이어야 합니다. 오차에 상관관계가 없어야 합니다. 개별 모델들이 무작위 예측을 수행하는 모델보다 성능이 좋은 경우에 사용합니다. 종류는 보팅(Voting), 배깅(Bagging), 스태킹(Stacking), 부스팅(Boosting)이 있습니다. Random Forest는 배깅, GBM, Xgboost, LightGBM은 부스팅을 사용합니다.
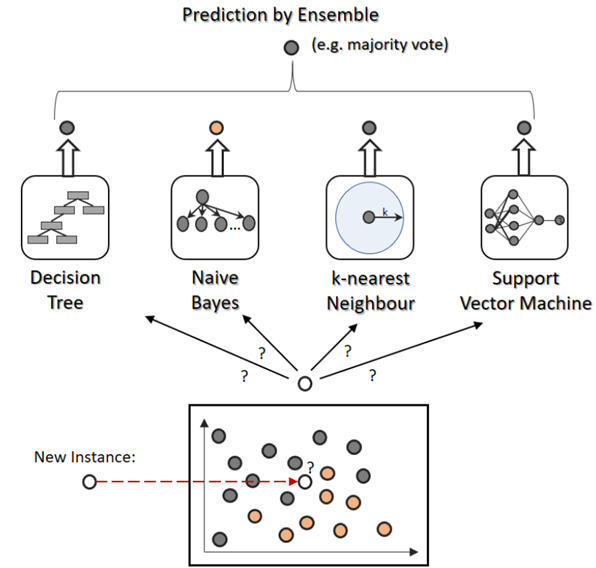
보팅(voting)
보팅은 여러 개의 분류기가 투표를 통해 최종 예측 결과를 결정하는 방식입니다. 여러 개의 분류기의 마지막 과정에 통해 최종적인 예측 결과를 결정합니다. 서로 다른 알고리즘을 여러 개 결합하여 사용하게 됩니다. 방식에 따른 아래와 같이 분류할 수 있습니다.
- 하드 보팅 : 가장 많은 표를 얻은 결과 선택
- 소프트 보팅 : 예측한 확률을 합산해 가장 높은 분류 결과 선택
- 가중치 투표 : 가중치를 줘서 높은 점수가 나오는 결과 선택
배깅(Bagging)
배깅은 샘플링 기법 중 하나로 1996년 Breiman에 의해 소개되었습니다. 샘플링 방법은 Bagging (Bootstrap Aggregating)와 Pasting이 있습니다. 참고로 Bootstrap은 신발에서 혼자 신을 수 있게 돕는 끈을 의미하며, 외부 input 없이 데이터를 추출하는 것을 말합니다.
배깅(bagging)은 각 모델은 서로 다른 학습 데이터를 사용합니다. 각 데이터는 복원 추출(Sampling with replacement)을 통해 원래 데이터의 수만큼의 크기를 갖도록 샘플링하게 됩니다. 여기서 복원 추출은 한번 뽑은 것을 다시 넣고 뽑는 것을 말합니다. 추출 과정에서 같은 데이터가 여러 번 나올 수도 있고 한 번도 선택되지 않을 수도 있습니다.
여기서 개별 데이터셋을 ‘부트스트랩셋’이라 부릅니다. m개의 분류기를 집계(Aggregating)하여 최종적으로 결합합니다. 집계할 때 분류일 경우는 통계적 최빈값을 사용합니다. 회귀일 경우는 평균을 계산하여 사용합니다. 마지막으로 페이스팅(Pasting)은 중복을 허용하지 않고 샘플링하는 방식을 말합니다.
스태킹(Stacking)
스태킹은 여러 가지 모델들의 예측값을 최종 모델의 학습 데이터로 사용하는 예측하는 방법입니다. 예를 들면, K-NN, Logistic regression, Random forest, xgboost 모델을 이용해서 4종류의 예측값이 나오게 되면 그 예측값을 최종모델의 샘플 데이터로 사용합니다.
결국 여러 모델의 결과(output)를 input으로 사용한다는 이야기입니다. 그리고 최종모델로 선정된 LightGBM으로 최종 예측하게 됩니다. 여기서 최종모델을 메타모델이라 말하기도 합니다.
스태킹은 활용 관점에서 볼 때, 성능이 무조건 좋아지는 것은 아닙니다. 현실 비즈니스 모델로 구축되어 많이 사용되지는 않습니다. 다만 성능이 올라가는 경우가 더러 있기 때문에 캐글이나 데이콘과 같은 미세한 성능 차이로 승부를 결정하는 대회에서 대안이 될 수 있습니다. 특히 기본 모델로 4개 이상을 선택해야 좋은 결과를 기대할 수 있습니다.
'데이터 분석' 카테고리의 다른 글
| 랜덤 포레스트(Random Forest) 장단점 - 특성(변수) 중요도 (0) | 2023.09.22 |
|---|---|
| 랜덤 포레스트(Random Forest) 동작 원리 및 OOB, Random Subspace (0) | 2023.09.21 |
| 의사결정나무(Decision Tree) 종류 및 학습 - 장단점 (0) | 2023.09.19 |
| 의사결정나무(Decision Tree) 특징 및 동작 원리 - 불순도 알고리즘 (1) | 2023.09.18 |
| K-NN(Nearest Neighbor) 차원의 저주, 장단점, weighted K-NN (0) | 2023.09.17 |



