이전 포스팅에서 K-NN 알고리즘의 특정에 대해서 살펴 보았다면 이번 포스팅에서는 장단점과 K-NN에서 왜 차원에 저주가 나타나는지에서 대해 포스팅해 보겠습니다.
K-NN에서 전처리(pre-processing) 작업은 필수적입니다. 왜냐하면 값의 범위가 큰 feature 일수록 거리 계산에 영향을 많이 주기 때문에 더 중요한 변수로 인식될 수 있습니다. 따라서 값의 범위를 맞추어 주는 Scaling, Normalization, Standardinzation 등의 방법을 적용해 주는 것이 중요합니다.
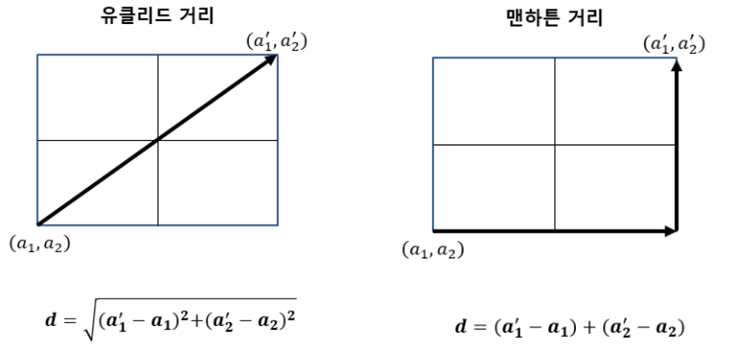
K-NN의 주요 하이퍼파라미터 중 하니인 거리(distance)는 두가지 정도를 많이 사용합니다. 첫째, 유클리디안 거리(Euclidean Distance)는 두 점 사이의 최단 거리를 이용하는 것입니다. 우리가 생각하는 일반적인 거리입니다.
두 번째, 맨하튼 거리(Manhattan Distance)는 한 번에 한 축 방향으로 움직일 수 있을 때 두 점사이의 거리를 말합니다. 맨하탄 시내에서 거리를 이동할 때 가로지를 수 없어 생각한 거리라고 보시면 됩니다. 중요한 것은 거리를 사용하기 때문에 Scaling을 꼭 필요하다는 것입니다.
차원의 저주(Curse of Dimension)
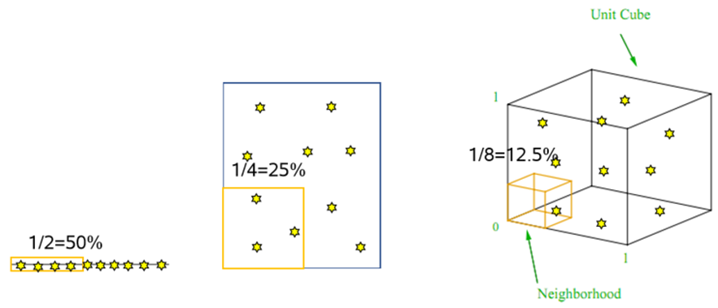
K-NN의 특징 중 하나가 데이터의 차원이 증가할 수록 성능 저하가 심합니다. 각 변수의 50% 영역에 해당하는 데이터가 있다고 가정할 경우 차원 증가와 함께 그림[차원의 저주]과 같이 설명 면적 줄어듭니다. 데이터의 차원이 증가할수록 데이터가 이루는 공간의 부피가 기하급수적으로 증가하기 때문입니다.
동일한 개수의 데이터 밀도가 희박(Sparse)해지기 때문에 분석을 위해서는 더 많은 데이터가 필요합니다. 차원이 늘어나면서 데이터가 공간을 설명하기에 부족해지는 현상이 발생합니다. 이런 현상은 적은 데이터로 공간을 설명하기 때문에 모델의 과적합(Overfitting) 문제 발생 시킵니다. 결국 모델 성능 나빠지게 하는 원인이 됩니다.
차원의 저주 극복 방법
여기서는 차원의 저주를 극복하는 방법 두가지를 말씀드리겠습니다. 첫째, 사전지식 활용하여 피처(feature) 선택하는 것입니다. 그러면 차원을 줄일 수 있습니다. 둘째, 모델의 smothness를 증가시키는 것입니다. 이것은 k값 증가시키면 됩니다. 결국 모델의 성능이 나빠지는 경우 궁극적 해결 방법은 차원(feature)을 줄이는 것입니다.
장점
K-NN 알고리즘의 장점은 첫쩨, 간단하고 직관적이라는 것입니다. 학습과정이 없고 분석 결과를 이해하기 쉬습니다. 둘째, 특별한 수학적 또는 통계적 가정이 필요 없습니다. 기존 데이터를 기반으로 하기 때문에 데이터에 대한 가정이 없습니다. 선형 회귀처럼 가정이 필요 없습니다. 셋째, 모형 적합(학습) 과정이 필요 없습니다. 생각해 보면 알겠지만 K-NN은 학습하지 않습니다.
넷째, 훈련 데이터에 노이즈가 있어도 적용이 가능합니다. 이는 k값 결정에 따라 처리할 수 있습니다. 가까운 상위 k개의 데이터만 활용하기 때문에 오류 데이터는 비교 대상에서 제외됩니다. 그래서 훈련 데이터의 노이즈에 큰 영향을 받지 않습니다. 다섯째, 모델의 결과가 일관성을 가집니다. 기존 분류 체계 값을 모두 검사하여 비교하므로 정확도가 높습니다. 실예로 학습 데이터 수가 충분하면, 상당히 좋은 성능 보장합니다.
단점
K-NN 알고리즘의은 첫째, 과적합(Overfitting)의 위험성이 큽니다. 둘째, 주변부로 가면 왜곡되는 경향이 존재합니다. 이것은 모델의 특성이기도 합니다. 셋째, 성능 가변적입니다. k값을 어떻게 선정하는지에 따라 알고리즘 성능 좌우 됩니다. 넷째, 주 알고리즘 로직인 거리 계산 비용이 큽니다. 기존 모든 데이터를 거리를 비교하기 때문에 데이터가 많을수록 처리 시간 증가합니다.
다섯째, 많은 데이터 활용을 위해 메모리를 많이 사용하므로 고사양의 하드웨어 필요합니다. 여섯째, 차원의 저주 가능성이 높습니다. 높은 자원일수록 자원의 요구량은 더 커집니다. 고차원의 데이터에 대해서는 kNN을 수행하기 위해서는 차원 축소가 필요합니다. 일곱째, 지나치게 데이터 의존적입니다. 최적 이웃의 수(k)와 사용할 거리 척도를 데이터 각각의 특성에 맞게 연구자가 임의로 설정 필요합니다. 데이터와 업무를 얼마나 잘 아는지가 관건이 됩니다.
Weighted k-NN
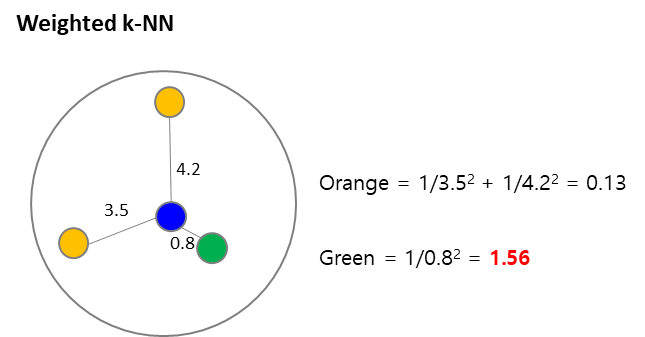
K-NN 알고리즘의 방법의 단점을 보완하여 Weighted k-NN(가중 k-최근접이웃) 입니다. 이 알고리즘의 아이디어는 단순 K개가 아니라 가까운 이웃에 대해서는 더 높은 가중치를 부여하자는 것이었습니다. Weighted k-NN의 거리가 가까울수록 Weight를 높게 설정합니다. 거리에 역을 취해 계산한다고 생각하면 이해가 쉽습니다. 중요한 변수와 불필요한 변수가 섞여 있다면 중요한 변수를 선별하거나 역시 Weight를 주는 방법을 생각해 볼 수 있습니다.
K-NN 회귀
K-NN Regression(회귀)는 분류와 방식은 동일합니다. 마지막에 이웃 간의 평균을 계산하여 예측 값으로 사용하는 방식입니다. 예를 들어, 3-NN for regression이라고 할 때 주변의 세 점이 50, 55, 51이 있다고 하겠습니다.
그러면 계산식은 ( 50+55+51)/3 = 52가 됩니다. 회귀 모델이기 때문에 R-square 값으로 예측 적합도를 측정할 수 있습니다.
K-NN 고려사항 및 활용 분야
다시 한번 강조하지만 데이터 전처리 과정이 중요한 알고리즘 입니다. 특성 선택, Sacaling 등에 신경 써야 합니다. 그리고 예측이 느리고 많은 특성 처리하는 능력이 부족해 실제 업무에서 많이 사용하지는 않습니다. 활용 분야는 위치 측위(MS RADAR) 에서 이동 객체의 위치에서 AP 신호 강도 측정하여 이동 객체 위치 최종 추정하는 데 사용합니다.
추천 시스템에서 사용자 추천정보 기반 성향 및 구매 패턴 분류하는데 사용합니다. 포털 등의 중복, 문서 분류, 유사 게시글 필터링 등 데이터 필터링에 사용됩니다.
* 함께 보면 좋은 글
K-NN(Nearest Neighbor) 알고리즘 - 사례 기반 학습
이번 포스팅은 K-Nearest Neighbor(K-최근접 이웃) 알고리즘에 대해 특징과 학습 방법에 대해 알아보도록 하겠습니다. K-NN은 K-means 알고리즘과 많이 헷갈리는데요. 이번 기회에 정확이 알고 갈 수 있었
bommbom.tistory.com
'데이터 분석' 카테고리의 다른 글
| 의사결정나무(Decision Tree) 종류 및 학습 - 장단점 (0) | 2023.09.19 |
|---|---|
| 의사결정나무(Decision Tree) 특징 및 동작 원리 - 불순도 알고리즘 (1) | 2023.09.18 |
| K-NN(Nearest Neighbor) 알고리즘 - 사례 기반 학습 (0) | 2023.09.15 |
| [머신러닝] 로지스틱 회귀 학습 - Log Loss, 크로스 엔트로피 (2) | 2023.09.14 |
| [머신러닝] 로지스틱 회귀 - 승산(Odds)과 활성화 함수 (0) | 2023.09.13 |



