이번 포스팅에서는 모수와 비모수에 대해 알아보도록 하겠습니다. 통계학이나 머신러닝을 공부하다 보면 모수, 비모수라는 단어가 나옵니다. 그런데 이 단어의 의미를 어렴풋이 짐작할 뿐 정확하게 따져보지 않는데요. 이 개념을 알아둔다면 우리가 사용하는 모델을 더 잘 이해하는데 도움이 될 거라 생각합니다.
통계적 의미
모수와 비모수에 대해 말하기 전에 먼저 확률분포에 대해 알고 있어야 합니다. 확률분포는 샘플(관측치)들이 가질 수 있는 수치 값들의 표현입니다. 보통 0과 1사이의 확률로 표현할 때 이 확률 값들의 패턴을 봅니다. 그리고 확률함수는 샘플 데이터가 가질 수 있는 값들을 확률로 표현하기 위해서는 대응 함수를 말합니다.
- 이산확률함수는 확률질량함수(PMF)로 표현
- 연속확률함수는 확률밀도함수(PDF)로 표현
정규분포의 경우 평균과 분산(표준편차)이라는 두개의 모수를 가지고 있으며 확률분포의 모양을 결정합니다. 여기서 모수라는 단어가 나왔는데요. 우리는 이 모수가 어떤 것일까를 추정하게 됩니다. 그것을 모수 추정(Estimation)이라 하고 통계학에서 모수를 추측하는 과정인 것입니다.
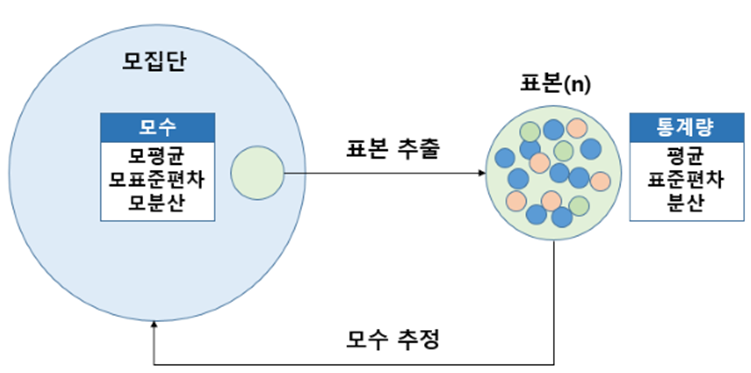
모수 모델 vs 비모수 모델
앞에서 우리는 모수에 의미에 대해 알았습니다. 그렇다면 우리가 사용하는 모델(알고리즘)을 모수와 비모수 모델로 구분해 보겠습니다.
- 모수적 모델
- 확률분포를 기반으로 해당 모수를 추정하는 과정이 포함된 모델
- 예를 들어, 선형회귀 – 정규분포를 가정(중심극한정리)
- 비모수 모델
- 세미모수적 모델
- 모수는 존재하나 확률분포는 무관한 모델
- 예들 들어, 인공신경망, 서포트벡터머신(SVM)
결론적으로 구분 기준은 분포 사용유무, 모델에 모수가 존재하는지 여부에 따라 모수(parameter)가 있으면 모수적 모델, 없으면 비모수적 모델로 생각하면 됩니다.
모수 vs 하이퍼모수
모수는 영어로는 parameter(파라미터)이고 매개변수라고도 합니다. 파라미터는 모델 내부에서 결정되게 되는 변수입니다. 이렇게 실제 모델을 결정하는 변수를 파라미터라고 합니다. 파라미터는 모델을 생성하면서 자동으로 머신이 찾아주는 값입니다. 그런데 모델을 결정하는 변수 이외에도 모델을 생성하기 위해 필요한 변수들이 있습니다. 이 변수를 하이퍼파라미터라고 하고 사용자가 직접 세팅해줘야 하는 값들입니다. 하이퍼파리미터를 어떻게 조정하냐에 따라 모델의 성능과 학습속도를 향상할 수 있습니다. 그래서 이 과정을 하이퍼파라미터 튜닝이라고 합니다. 물론 하아퍼파라미터는 정해진 최적의 값은 없습니다. 분석가의 경험에 의해 좌우되는 경우가 많습니다.
- 모수(parameter) : 계수, 편향 등
- 하이퍼모수(hyperparameter) : k개수, epoch수, learning rate 등
'데이터 분석' 카테고리의 다른 글
| 클러스터링 - 계층적 군집화 동작 원리, 장단점 (0) | 2023.10.13 |
|---|---|
| 클러스터링(clustering) 개념 - 군집분석 사례, 계층적 vs 분할적 군집 (0) | 2023.10.12 |
| 차원 축소 - 특잇값 분해(SVD) 및 PCA 관계 (0) | 2023.10.11 |
| 차원 축소 - t-SNE의 특징 및 PCA와 차이점 (1) | 2023.10.11 |
| 차원 축소 - PCA(주성분 분석), Explained Variance Ratio (1) | 2023.10.10 |



