머신 러닝 알고리즘 중에 가장 기본이 되는 모델이 선형 회귀(Linear Regression) 입니다. '왜 선형 회귀가 가장 기본이 됐을까요?' 저도 처음에 이런 생각을 했었는데요. 이유는 우리가 사는 세상에서 발생하는 일들의 상관관계가 선형으로 많은 부분 설명이 되기 때문입니다. 그러면 모델의 특징과 종류들에 대해 알아 보도록 하겠습니다.
Linear Regression의 특징은?
머신 러닝을 배우는 사람이라면 가장 먼저 배우게 되는 것이 Linear Regression 입니다. 어떻게 보면 가장 쉬운 개념이지만 공부해야 할 요소들도 많습니다. 그래서 선형 회귀를 잘 끝내 놓은 다면 다음 알고리즘도 이해가 쉽습니다. 알고리즘은 기본적으로 세상의 현상을 데이터를 통해 예측해 보는 것입니다.
선형 회귀를 간단하게 표현하면 X 값이 증가할 때 Y 값이 증가 또는 감소하는 데이터에 적합한 알고리즘 입니다. 여기서 X가 입력되는 값이고, Y는 출력되는 값, 즉 예측 값 입니다. 이런 설명을 수식으로 표현 하면 선형이 됩니다. 수식이 선형이라서 선형 회귀인 것이죠.
그러면 어떤 경우에 선형 회귀를 사용할까요? X의 특성들을 이용해 연속된 숫치형 Y변수를 예측하고 싶을 때 사용합니다.이름도 회귀인 것처럼 예측에 사용하는 것이죠. 만약 특성(feature)이 하나일 땐 직선, 두 개일 땐 평면, 더 높은 차원에서는 초평면으로 표현 됩니다. 이 알고리즘의 장점은 해석하기 쉽다는 것입니다. y = wx+b와 같은 방정식으로 표현이 가능하니까요. 아래 그림을 보면 쉽게 이해가 가실겁니다.
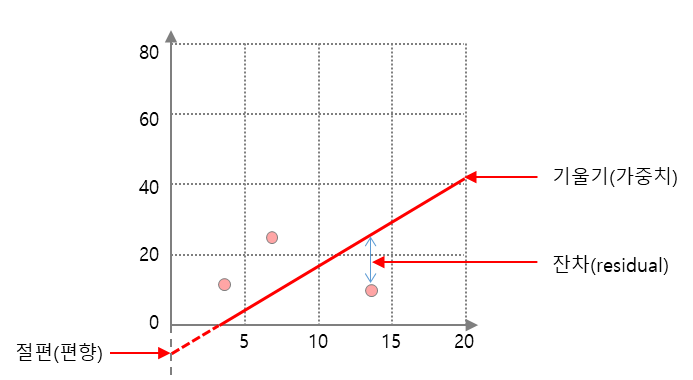
Linear Regression의 종류
선형 회귀의 종류는 독립 변수(x)의 개수 또는 수식 표현 함수가 몇 차 함수냐에 따라 달라집니다. 종류를 구별하기 매우 쉽습니다.
단순 선형 회귀 (Simple Linear Regression)
단순 선형 회귀는 독립변수가 1개인 선형 모델을 말합니다. 앞에서 예시를 들었던 기본 모델입니다. 독립 변수 x와 곱해지는 값 w를 머신 러닝에서는 가중치(weight)라고 합니다. 또 별도로 더해지는 값 b가 편향(bias) 입니다.
직선의 방정식에서는 각각 직선의 기울기와 절편(편향)을 의미합니다. 뒤에서 설명하겠지만 w와 b 값에 따라 달라지는 선형으로 대이터를 표현하는 알고리즘으로 생각하면 됩니다.
- 수식 y = wx + b
- w : 가중치=회귀계수(coefficient)
- b : 편향=절편
다중 선형 회귀 (Multiple Linear Regression)
단순 선형 회귀와 다르게 이번에는 독립변수가 2개 이상인 선형 모델을 말합니다. 집의 매매 가격은 단순히 집의 평수가 크다고 결정되는 게 아니라 집의 층의 수, 방의 개수, 지하철 역과의 거리 등 다수의 요소로 예측해야 합니다. 이를 예측하기 위해서는 다중 선형 회귀분석이 필요합니다. 현실 세계에서 예측은 대부분 다중 선형 회귀 입니다.
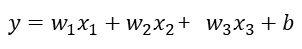
다항 선형 회귀 (Polynomial Linear Regression)
다항 선형 회귀는 독립변수 x와 종속변수 y사이에 상관관계가 있지만, 직선보다는 곡선으로 설명하는 것이 적합할 때 사용 합니다. 2차함수 이상의 다항함수를 이용해 두 변수 간의 선형관계 설명 할 수 있습니다. 가끔 다중 선형 회귀와 다항 선형 회귀를 헷갈려 하는 분들이 계신데, 다중 선형 회귀는 곡선이 아닙니다.
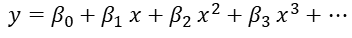
비용함수
모델의 최적화 모델을 위한 비용 함수에 대해 알아보겠습니다. 앞에서 w와 b를 결정하는 것이 중요하다고 했습니다. 그렇게 하기 위해서는 각 데이터의 점들을 대입해서 오차가 가장 작은 수식을 완성해야 합니다. 그래서 비용함수에는 잔차(residual)와 오차(error)라는 개념이 있습니다. 추정값과 얼마나 차이가 나는지 알아야 되기 때문입니다. 두 단어에 대해 설명하고 넘어가면 좋을 것 같습니다.
- 잔차 = 표본집단의 회귀식에서 예측된 값 - 실제 관측값
- 오차 = 모집단의 회귀식에서 예측된 값 - 실제 관측값
두개 모두 실제 관측값과의 차이는데 단지 표본집단이냐 모집단인지만 다릅니다. 그렇다면 표본집단과 모집단은 어떻게 다를까요? 통계학적으로 모집단은 전체 대상 및 전체 집합을 의미 합니다. 모집단을 대상으로 분석하는 방법을 전수조사라고 합니다. 하지만 물리적으로 전수조사가 어려운 경우가 많습니다. 그래서 모집단으로 부터 추출된 부분 집합인 표본집단을 사용 합니다.
또 한가지 미리 알아야 할 개념이 '분산' 입니다. 모든 통계는 결국 분산을 얼마나 잘 설명하는지가 목적 입니다. 각 점들을 표현하는 수식이 결국 분산을 표현하는 방식입니다. 결론적으로 회귀 분석이란 종속변수의 분산을 독립변수로 설명하는 과정이라고 할 수 있습니다.
비용함수를 사용하는 이유
왜 Cost Function(비용함수)을 사용할까요? 정답은 최적화된 모델을 만들기 위해서 입니다. 실제값과 예측값의 오차를 계산하여 모델의 오차를 최소화 할 수 있습니다. 오차가 최소화 됬었다는 것은 최적 모델이라는 이야기 입니다.
여기서 실제값과 예측값에 대한 오차 식을 비용 함수 또는 목적 함수(Objective function), 손실 함수(Loss function) 라고 말합니다. 가장 많이 사용하는 비용함수는 MSE와 크로스엔트로피가 있습니다. 크로스엔토리피에 관한 내용은 링크를 참고하세요.
평균제곱오차(MSE)
일반적으로 회귀 문제의 경우에는 주로 평균제곱오차(Mean Squared Error, MSE)를 사용 합니다. F(x) = Wx + b 에서 F(x) 가 우리가 가정한 가설(Hypothesis) 을 의미 합니다. 여기서 W(Weight) 가중치 값과 b(bias) 의 수치에 따라 선(line)의 모양이 달라지게 됩니다.
손실함수는 알고리즘이 얼마나 잘못 하고 있는지를 표현하는 지표 입니다. 값이 낮을수록 학습이 잘 된 것으로 판단할 수 있습니다. 이때 미분 가능한 함수를 사용해야 합니다.
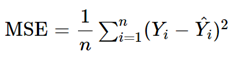
'데이터 분석' 카테고리의 다른 글
| [머신러닝] 선형 회귀 가정과 다중공선성 진단 및 해결 방법 (2) | 2023.09.11 |
|---|---|
| [머신러닝] 선형 회귀 - 옵티마이저와 학습률(Learning Rate) (0) | 2023.09.10 |
| [머신러닝] 과적합(Overfitting) 해소 방법 - 정규화 (2) | 2023.09.08 |
| [머신러닝] 과적합(Overfitting) 해소 방법 - 모델 단순화 (0) | 2023.09.07 |
| [머신러닝] 과대적합 vs 과소적합(overfitting, underfitting) (0) | 2023.09.06 |



