인공지능 시대에는 데이터 중심의 비즈니스 환경이라는 것은 부정할 길이 없습니다. 혹자는 데이터를 가장 많이 보유한 구글이 세계를 지배할 것이라는 말까지 하더군요.
하지만 난 생각이 좀 다릅니다. 데이터의 양뿐만 아니라 복잡성이 증가하면서 기존 중앙집중식 데이터 관리 방식은 한계를 드러내고 있기 때문입니다.
이런 문제를 해결하기 위해 등장한 데이터 메시(Data Mesh)는 혁신적인 데이터 관리 패러다임입니다. 혹시 생소하시다면 데이터 메시의 개념부터 구현까지, 핵심 내용을 들어보시죠.
데이터 메시란?
데이터 메시는 분산된 아키텍처 프레임워크를 사용하는 데이터 관리 접근 방식입니다. 기존의 중앙 집중식 데이터 웨어하우스나 레이크와 다르죠. 데이터의 소유권과 책임을 비즈니스 도메인별로 분산시키는 것이 특징입니다.
예를 들어, 대형 소매 기업에서 마케팅 부서는 고객 행동 데이터를, 판매 부서는 거래 데이터를 각각 소유하고 관리합니다. 각 부서는 자체 데이터 플랫폼을 통해 데이터를 관리하며, 다른 부서와의 데이터 공유는 API를 통해 이루어집니다
데이터를 각 도메인(예: 마케팅, 판매, 재무 등)이 독립적으로 소유하고 관리하도록 설계된 아키텍처입니다. 데이터 메시의 핵심은 데이터를 저장하고 분석하는 대상이 아닌 "제품"으로 간주하는 데 있습니다.
이를 통해 데이터 품질, 접근성, 활용성을 극대화할 수 있습니다. Thoughtworks의 Zhamak Dehghani가 2019년에 처음 제안한 이 개념은 대규모 조직에서 특히 유용하며, 다음과 같은 특징을 지닙니다.
- 분산형 소유권: 각 도메인이 자신들의 데이터를 책임지고 관리
- 셀프서비스 플랫폼: 기술적 장벽 없이 데이터를 활용할 수 있는 환경 제공
- 연합형 거버넌스: 자율성과 일관성을 모두 보장하는 데이터 관리 체계
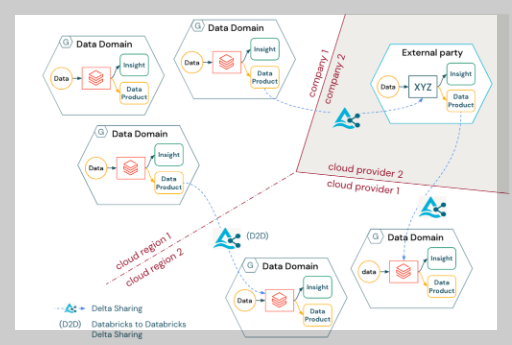
데이터 메시의 4가지 핵심 원칙
데이터 메시는 다음 네 가지 원칙에 기반합니다. 이 네 가지 원칙은 데이터 메시가 단순한 기술적 변화가 아니라 조직 문화와 운영 방식의 전환임을 보여줍니다.
| 원칙 | 설명 |
| 도메인 중심 데이터 소유권 |
각 도메인이 데이터를 직접 소유하고 관리하여 책임성을 강화합니다.
|
| 데이터를 제품으로 간주 |
데이터를 명확한 목적과 품질 기준을 가진 제품처럼 관리하며, 다른 도메인에서도 쉽게 사용할 수 있도록 제공합니다.
|
| 셀프서비스 데이터 플랫폼 |
데이터를 저장, 처리, 분석하는 데 필요한 기술과 도구를 제공하여 사용자 편의를 극대화합니다.
|
| 연합 컴퓨팅 거버넌스 |
조직 전체의 표준과 정책을 준수하면서도 각 도메인의 자율성을 보장합니다.
|
데이터 메시 아키텍처의 구성 요소
데이터 메시 아키텍처는 다음과 같은 주요 구성 요소로 이루어져 있습니다.
1. 데이터 도메인
- 각 도메인은 자신들의 데이터를 독립적으로 소유하고 관리합니다.
- 예: 마케팅 팀은 고객 행동 데이터를, 판매 팀은 거래 데이터를 관리
2. 데이터 제품
- 각 도메인이 제공하는 최종 결과물로서의 데이터입니다.
- API, 테이블, 보고서 등 다양한 형태로 제공되며, 사용자가 쉽게 접근하고 활용할 수 있도록 설계됩니다.
3. 셀프서비스 플랫폼
- 데이터를 저장하고 처리하는 데 필요한 기술적 인프라와 툴을 제공합니다.
- 사용자는 중앙 시스템에 의존하지 않고 독립적으로 데이터를 활용할 수 있습니다.
4. 연합 거버넌스
- 조직 전체에서 일관된 데이터 표준을 유지하면서도 각 도메인의 자율성을 보장합니다.
- 예: 보안 정책 준수, 데이터 품질 기준 설정
데이터 메시 도입의 이점과 구현 가이드
데이터 메시 도입 이점
- 확장성: 각 도메인이 독립적으로 데이터를 관리하므로, 데이터 양이 증가해도 병목 현상이 발생하지 않습니다.
- 데이터 품질 향상: 데이터를 가장 잘 이해하는 도메인 전문가들이 직접 관리함으로써 신뢰성과 정확성이 높아집니다.
- 빠른 의사결정: 셀프서비스 플랫폼을 통해 필요한 데이터를 신속하게 찾고 활용할 수 있습니다.
- 비용 효율성: 중앙 집중식 시스템에 비해 운영 및 유지 비용이 절감됩니다.
- 보안 및 규정 준수 강화: 연합 거버넌스를 통해 보안 정책과 규정을 효과적으로 적용할 수 있습니다.
데이터 메시 구현 가이드
1. 조직 문화 변화
- 중앙집중식에서 분산형으로 전환하기 위한 조직 내 합의와 협력이 필요합니다.
- 각 도메인 팀에 책임감을 부여하고 이를 지원하는 환경을 조성해야 합니다.
2. 기술 인프라 구축
- 셀프서비스 플랫폼을 구축하여 사용자가 쉽게 데이터를 저장, 처리, 분석할 수 있도록 해야 합니다.
- 클라우드 기반 솔루션이나 컨테이너화된 마이크로서비스 아키텍처를 활용할 수 있습니다.
3. 거버넌스 체계 설계
- 일관된 데이터 표준과 정책을 설정하여 전체적인 통제를 유지하면서도 유연성을 보장해야 합니다.
- 예: API 설계 표준화, 메타데이터 관리 정책
4. 점진적 도입
- 한 번에 모든 시스템을 변경하기보다는 특정 도메인부터 시작해 점진적으로 확장하는 것이 효과적입니다.
마치며
데이터 메시는 기존 중앙집중식 아키텍처의 한계를 극복하고 확장성과 유연성을 제공하는 혁신적인 접근 방식입니다. 하지만 구현 과정에서 조직 문화 변화, 기술적 복잡성, 인력 확보 등 여러 도전 과제가 있을 수 있습니다.
이러한 과제들을 성공적으로 극복하기 위해서는 단계적이고 체계적인 접근이 필요합니다. 위 글에서는 개념부터 구현까지 데이터 메시에 대해 다뤘습니다. 이제 실제 사례에서 구체적인 기술 스택에 대한 정보로 나아가시기 바랍니다.
'데이터아키텍처' 카테고리의 다른 글
| 가트너가 주목한 데이터 패브릭, 기업 데이터 관리 혁신 가져올까? (0) | 2025.01.04 |
|---|---|
| 데이터 민주화의 모든 것: 의미부터 구현까지 완벽 가이드 (2) | 2025.01.03 |
| MySQL UPDATE JOIN 방법과 주의 사항 (0) | 2024.12.04 |
| 오라클 인덱스 힌트 강제 사용 방법, 성능 최적화 가이드 (0) | 2024.11.21 |
| MySQL binlog 포맷 (Statement, Row, Mixed) 무엇이 다를까? (0) | 2024.11.11 |



