Seq2Seq(Sequence-to-Sequence) 모델은 기계 번역, 챗봇, 요약 등 시퀀스 데이터를 입력으로 받아 다른 시퀀스 데이터를 출력하는 데 사용되는 인공 신경망 모델입니다. 이 모델은 대표적으로 인코더-디코더(Encoder-Decoder) 구조를 기반으로 하는데요. 이글에서는 원리, 특징, 문제점을 알아보고 RNN과 어떻게 다른지를 살펴보겠습니다.
Seq2Seq 원리
Seq2Seq은 sequence to sequence의 줄입말입니다. '싯투싯'이라고 읽기도 합니다. 이름에서 알 수 있듯이 시계열에 또 다른 시계열로 변환한다는 의미입니다. 이미 말했지만 seq2seq를 Encoder-Decoder 구조입니다. Encoder는 입력 데이터를 인코딩하고, Decoder는 인코딩 된 데이터를 디코딩(복호화)합니다.
1. 인코더 (Encoder)
Encoder 역할은 입력된 텍스트를 숫자 형태 혹은 벡터 형태로 어떻게 변환하여 저장하는 것입니다.
- 입력 시퀀스를 고정된 길이의 벡터 형태로 변환합니다.
- 주어진 입력 시퀀스의 각 요소를 순차적으로 처리하고, 이를 토큰 임베딩과 함께 인코더 신경망에 주입합니다.
- 인코더는 입력 시퀀스를 고정된 길이의 문맥 벡터로 압축하고, 입력 시퀀스의 의미를 인코딩합니다.
2. 디코더 (Decoder)
Decoder 역할은 Encoder에 의해 숫자로 변경된 정보(vector)를 다른 형태의 텍스트 데이터로 변환하는 것입니다. 어떻게 풀어어 반환할 것인지 역할을 합니다.
- 인코더에서 생성된 문맥 벡터를 기반으로 출력 시퀀스를 생성합니다.
- 디코더는 초기 상태로 인코더의 문맥 벡터를 받아들이고, 출력 시퀀스의 첫 번째 토큰을 생성합니다.
- 생성된 토큰은 다음 시간 단계에서 디코더의 입력으로 사용됩니다. 이러한 과정은 종료 토큰이 생성될 때까지 반복됩니다.

Encoder와 Decoder를 위해 순환신경망 기반 모형 사용 가능합니다. 두개의 RNN(LSTM)을 연결하여 만들 수 있다는 이야기입니다. 그림처럼 ‘Je suis etudiant‘ → 'I am a student'로 번역 할 수 있습니다. 이때 입력 단어의 개수와 출력 단어의 개수가 동일할 필요는 없습니다. Encoder와 Decoder가 시계열 데이터로 변환합니다.
Seq2Seq 특징
Seq2Seq은 RNN의 가장 발전된 형태의 아키텍처 중 하나입니다. 이는 다양한 기계번역에 탁월한 성과를 보여준 아키텍처입니다. LSTM, GRU 등의 RNN Cell을 길게 쌓아서 방대한 양의 Sequence를 처리하는데 특화된 모델이라 할 수 있습니다.
하지만 Seq2Seq 문제점도 있습니다. 문장의 길이가 긴 경우 품질 저하가 발생합니다. 이런 경우 Feature Vector에 특징을 담아내기 어렵기 때문에 번역 등의 품질이 낮아지게 됩니다. 이는 고정길이의 Context Vector에 다 담기 어렵기 때문에 발생합니다.
그래서 Seq2Seq의 경우 대략 20개 정도의 단어 수준의 문장에서 최적의 성능을 보입니다. RNN의 공통적인 단점인 병렬처리에 대한 어려움도 여전히 가지고 있습니다. 아키텍처 구조가 Sequence로 입력을 다 받은 후에야 Decoding이 가능해지기 때문입니다. 이런 문제들 때문에 향후 어텐션(Attention)이라는 아이디어가 나오게 됩니다.
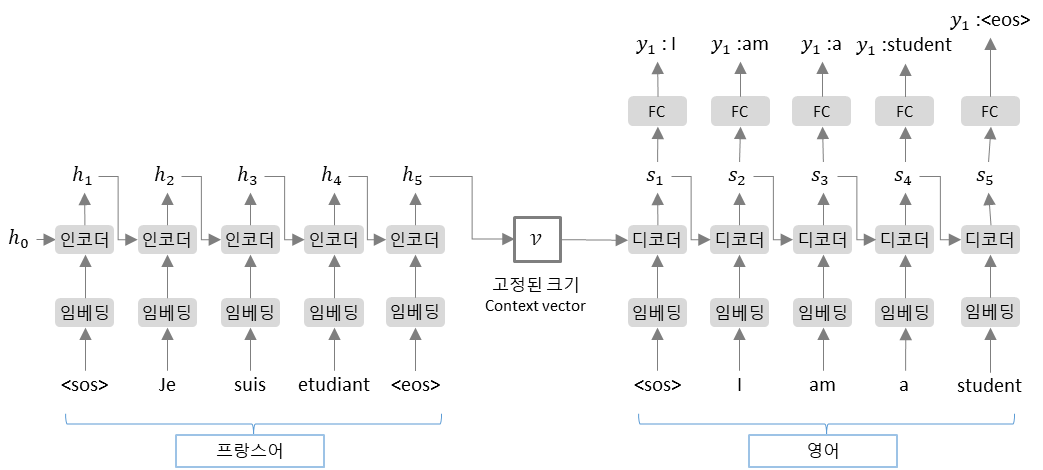
- $ x_{t} $ : 현재의 입력 단어
- $ h_{t} $ : 지금까지 입력된 문장에 대한 정보를 담은 벡터 표현
- $ s_{t} $ : 지금까지 출력된 문장에 대한 정보를 담은 벡터 표현
- $ y_{t} $ : 현재의 출력 단어
- sos : 문장의 시작(start of string)
- eos : 문장의 끝(end of string)
RNN과 어떻게 다를까?
그렇다면 Seq2Seq 모델과 RNN 모델의 차이점이 무엇일까요? RNN으로면 문장 생성을 한다고 할 때 어떤 방식으로 출력할지 생각해 볼 수 있습니다. RNN 언어 모델은 다음에 출현한 단어의 확률 분포를 이용하여 출력을 결정합니다.
- 결정적(deterministic) 방법 : 확률 가장 높은 단어 선택 → argmax
- 확률적(probabilistic) 방법 : 확률에 맞게 샘플링 선택 → sotfmax
확률분포 출력과 샘플링 작업을 원하는 만큼 반복하면 새로운 문장을 생성할 수 있습니다. 중요한 것은 생성한 문장은 훈련 데이터에는 존재하지 않는 말 그대로 새로운 생성된 문장이라는 것입니다. 언어 모델은 훈련 데이터를 암기한 것이 아니라, 훈련 데이터에서 사용된 단어의 정렬 패턴을 학습한 것이기 때문입니다.
결론적으로 언어 모델이 말뭉치로부터 단어의 출현 패턴을 올바르게 학습할 수 있다면, 그 모델이 새로 생성하는 문장은 우리 인간에게도 자연스럽고 의미가 통하는 문장이라는 지점이 의미가 있다고 할 수 있습니다. 하지만 하나를 입력받아 출력하는 방식은 어순이 맞지 않는 경우에는 제대로 예측하기 어렵습니다. 이런 한계 때문에 인코더를 수행 후 문맥벡터를 사용하는 아키텍처가 나오게 된 것입니다.
Seq2Seq 처리 절차
- 인코더는 입력 문장의 모든 단어들을 순차적으로 입력받습니다. 그리고 마지막에 이 모든 단어 정보들을 압축해서 하나의 컨텍스트 벡터(context vector)를 생성합니다.
- 입력 문장의 정보가 하나의 컨텍스트 벡터로 모두 압축되면 인코더는 컨텍스트 벡터를 디코더로 전송합니다.
- 디코더는 컨텍스트 벡터를 받아서 번역된 단어를 한 개씩 순차적으로 출력합니다.
아래는 유명한 Alammar Blog 블로그에서 가저온 이미지입니다. Seq2Seq 처리 절차를 애니메이션 형태로 이해하기 쉽게 보여줍니다. 자세한 내용은 블로그를 참고해 보셔도 좋습니다.
*함께 읽으면 좋은 글
Seq2Seq의 5가지 활용 방법, 어디에 활용될까?
자연어 처리(NLP) 영역에서 Seq2Seq 모델은 언어 이해와 생성의 강력한 아키텍처로 자리 잡았는데요. 원래 기계 번역 작업을 위해 도입된 Seq2Seq는 초기 애플리케이션을 뛰어넘어 챗봇 및 텍스트 요
bommbom.tistory.com
'딥러닝' 카테고리의 다른 글
| Seq2Seq의 5가지 활용 방법, 어디에 활용될까? (0) | 2024.05.14 |
|---|---|
| 어텐션 메커니즘(Attention mechanism) 아이디어와 종류 (0) | 2024.05.09 |
| 가중치 공유를 하는 이유 (0) | 2024.05.07 |
| GRU 성능 분석 및 특장점 (0) | 2024.05.01 |
| LSTM 모델의 의미와 장단점 (0) | 2024.04.25 |



