『 '데이널'의 컨텐츠에 포함된 정보는? 』
S3는 데이터 형식에 관계없이 무제한으로 저장이 가능하며 요금이 저렴한 스토리지 서비스입니다. 이는 AWS S3와 오브젝트 스토리지 이해 라는 글에서 설명했었죠. 이글에서는 개발자라면 꼭 알아야 할 S3의 특징과 활용법에 대해 이야기해 보겠습니다.
S3 데이터 저장 및 요금 정책
우선 S3에 데이터를 저장하는 방법부터 알아야 하는데요. AWS S3에 데이터를 저장하는 방법은 일반적으로 AWS 관리 콘솔, AWS CLI 그리고 AWS SDK를 이용한 방법이 있습니다.
다음과 같은 절차로 진행합니다.
1. 버킷 생성: S3에서 데이터를 저장하는 공간인 버킷을 생성합니다.
2. 파일 업로드: 생성된 버킷에 파일을 업로드합니다.
3. 객체 관리: 업로드된 파일(객체)에 대한 메타데이터 관리, 버전 관리 등 다양한 작업을 수행합니다.

AWS CLI를 이용한 오브젝트 업로드에 대한 예시입니다.
$ aws s3 cp local_file.txt s3://bucket명/ |
S3 스토리지 요금 - 아시아 태평양(서울) 기준
| S3 Standard | Strorage 요금(월별) |
| 처음 50TB/월 | GB당 0.023 USD |
| 다음 450TB/월 | GB당 0.022 USD |
| 500TB 초과/월 | GB당 0.021 USD |
높은 내구성과 가용성
S3는 강력한 내구성과 높은 가용성을 제공하는데요. 데이터의 유실 가능성이 매우 낮고, 저장된 데이터의 사용시간이 길다는게 특징입니다.
가용성 : 저장된 데이터를 정상적으로 사용할 수 있는 것을 의미, 99.99% 가용성
S3는 내구성과 가용성을 높게 설계하기 위해 최소 3개의 물리적으로 분리된 AZ(Available Zone)에 자동으로 데이터를 저장합니다. 이는 하둡이 최소 3개 이상의 데이터 노드를 관리하는 이치와 같은 맥락입니다.
강력한 읽기 일관성
AWS S3는 강력한 read-after-write consistency를 제공합니다. 이는 객체의 최신버전에 대한 즉시 읽기가 가능하게 합니다. 2006년 출시 이후, S3는 데이터를 안전하게 저장하고, 빠르게 접근할 수 있도록 설계되었습니다.
처음에 설계된 이벤트 일관성은 S3와 같은 분산 시스템에서 데이터를 업데이트한 후, 모든 시스템에서 그 변경 사항이 바로 반영되는 것이 아니라, 일정 시간이 지난 후에 반영되었는데요.
강한 읽기 일관성은 모든 시스템에서 항상 가장 최신의 데이터를 보여주지만, 이벤트 일관성은 일정 시간이 지난 후에 데이터가 일관성을 갖게 됩니다.
| 특징 | 설명 |
| 모든 작업에 대한 강력한 일관성 | GET, PUT, LIST 등 모든 작업과 객체 태그, ACL, 메타데이터 변경 작업에 적용 |
| 데이터 일관성 보장 | write한 데이터를 바로 read할 수 있어 데이터 무결성 향상 |
| 복잡성 감소 | 이벤트 일관성을 위한 별도의 처리가 필요 없어 개발이 간편해짐 |
| 비용 절감 | EMRFS Consistent View, S3Guard 등 추가 도구가 필요 없어 비용이 절감됨 |
| 성능 저하 없음 | 초당 수백 번의 객체 업데이트가 가능하며 성능 저하 없이 사용할 수 있음 |
아래는 강력한 읽기 일관성에 대한 그림입니다.
S3 좀 다른 파일 변경 방식
S3는 객체 변경 기능이 없어 객체 rename 작업 시, 파일 자체를 직접 수정하는 대신 새로운 객체를 생성하는 방식으로 파일명을 변경합니다. 즉, 기존 파일과 동일한 버킷 내에서 새로운 키(key)를 가진 객체를 생성하는 방식입니다.
파일명 변경 절차는 아래와 같습니다.
새로운 키 생성: 기존 파일의 키를 변경하고 싶은 새로운 이름으로 설정합니다.
새로운 객체 생성: 새로운 키를 사용하여 기존 파일의 내용을 복사하여 새로운 객체를 생성합니다.
기존 객체 삭제: (선택 사항) 더 이상 필요하지 않은 기존 객체를 삭제합니다.
AWS CLI를 이용한 오브젝트명 rename 예시입니다.
| # 기존 파일 키: old_file.txt # 변경할 파일 키: new_file.txt # 새로운 객체 생성 (덮어쓰기) aws s3 cp s3:// bucket명/old_file.txt s3://bucket명/new_file.txt # 기존 객체 삭제 (선택 사항) aws s3 rm s3:// bucket명/old_file.txt |
S3에 업로드 된 객체 파일의 내용 변경은 불가하므로 따로 복사해서 수정합니다. 다시 말해 기존 파일을 새로운 파일로 덮어쓰는 것입니다. 즉, 동일한 키(key)를 가진 새로운 객체를 업로드하는 방식입니다.
주의할 점은 S3는 “휴지통” 과 같은 기능이 없어 객체를 삭제하면 복구는 불가능합니다.
S3 Throughput(처리량) 제약사항
S3는 prefix당 매초 3500개의 PUT/COPY/POST/DELETE 요청 또는 5500개의 GET/HEAD 요청을 전송할 수 있습니다. 그 이상 발생할 경우 요청 지연이 발생할 수 있습니다. 해결 방법은 Prefix를 여러 개 만들어 I/O 요청을 병렬화 하는 것입니다.
S3에서 Prefix는 버킷 내에 가상의 폴더 구조를 만들어 객체를 논리적으로 분류하는 데 사용됩니다. 실제로 S3에는 파일 시스템과 같은 폴더 개념은 없지만, Prefix를 사용하여 마치 폴더처럼 객체를 관리할 수 있습니다. 그리고 처리량을 분산하는 효과가 있습니다.
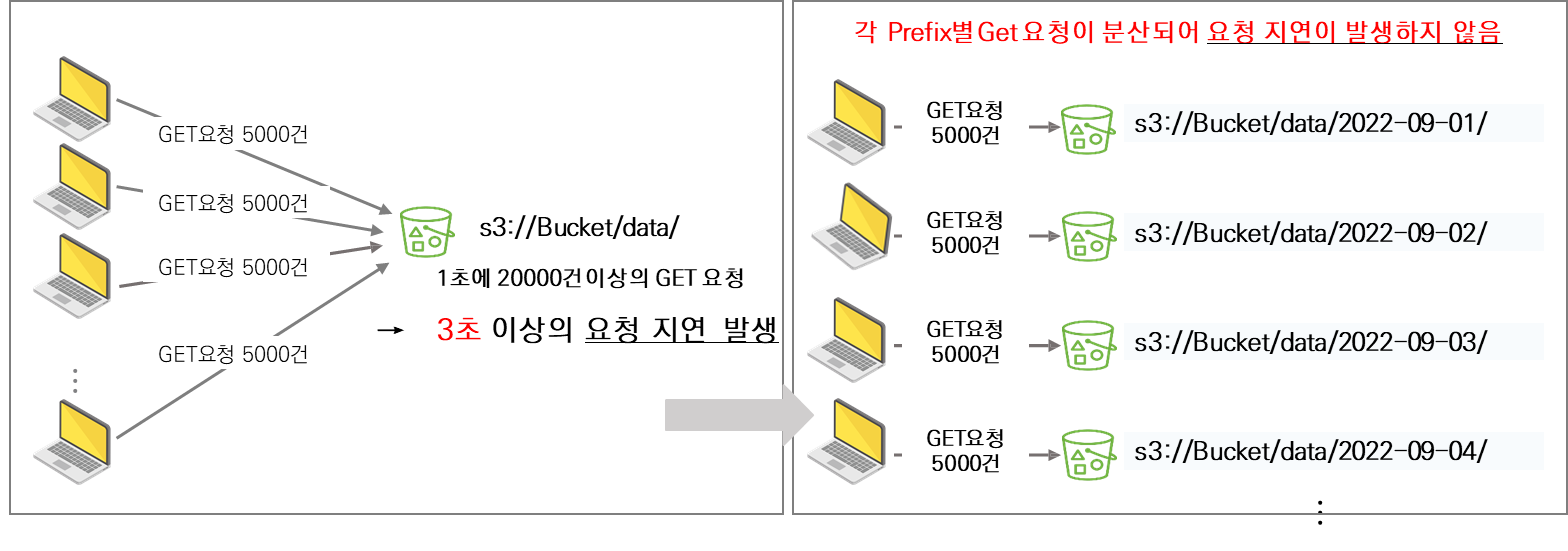
1. Prefix를 사용하는 이유
| 구분 | 설명 |
| 객체 관리 | 수많은 객체를 효율적으로 관리하고 찾기 쉽도록 폴더 구조를 만들 수 있습니다. |
| 데이터 분류 | 데이터의 종류, 생성 날짜, 프로젝트 등 다양한 기준으로 객체를 분류하여 관리할 수 있습니다. |
| 접근 제어 | Prefix별로 다른 접근 권한을 부여하여 보안을 강화할 수 있습니다. |
| IO 분산 | Prefix별로 Get 요청이 분산되어 요청 지연을 방지할 수 있습니다. |
| 라이프 사이클 관리 | Prefix별로 다른 라이프 사이클 규칙을 적용하여 저장 비용을 절감할 수 있습니다. |
2. Prefix 활용 시 주의 사항
Prefix를 명명할 때 몇가지 주의 사항이 있는데요. Prefix 길이에는 제한이 없지만, 너무 길면 관리가 어려울 수 있습니다. 또 동일한 Prefix를 사용하면 객체를 찾을 때 혼란이 발생할 수 있으니 명명 규칙이 있어야 합니다. 결과적으로 Prefix 구조를 일관되게 유지하여 관리 효율성을 높일 수 있습니다.
'빅데이터,클라우드' 카테고리의 다른 글
| Datadog으로 AWS MySQL 성능 저하의 원인을 찾아내는 방법 (1) | 2024.10.24 |
|---|---|
| AWS S3 버킷과 오브젝트 스토리지 이해하기 (2) | 2024.09.19 |
| AWS EC2, 어렵지 않아요! 간단하고 빠르게 시작하는 방법 (2) | 2024.09.11 |
| Amazon RDS 모니터링, CloudWatch로 느린 쿼리 수집 튜닝 (0) | 2024.07.30 |
| AWS 모니터링, CloudTrail, Config, CloudWatch 비교 (0) | 2024.07.24 |



