이번 포스팅에서는 하둡이 왜 나왔는지? 그리고 하둡 에코시스템은 무엇인지 그 특징들을 알아보도록 하겠습니다. 사실 하둡 에코시스템이라고 하면 그 안에 너무 많은 솔루션들이 있어 이번 포스팅에서 모두 다루기는 힘듭니다. 이번에는 데이터를 저장하는 저장소 관점에서 살펴보도록 하겠습니다.
Hadoop의 출현 배경
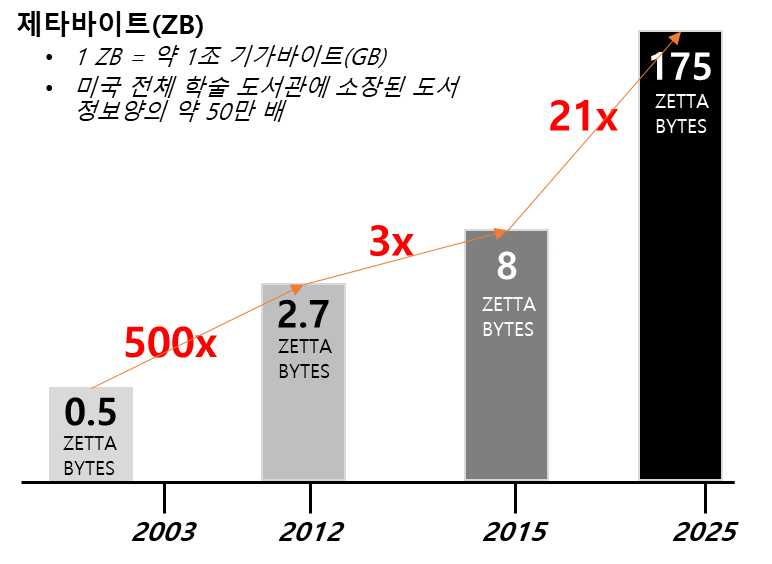
2000년대에 오면서 문자, 음성, 영상 등 비정형 데이터 급증하기 시작합니다. 이유는 스마트폰 확산이 가속하시켰다고 볼 수 있습니다. 2007년 6월, 스티브잡스가 아이폰을 처음 공개하면서 그 시장은 더욱 커지기 시작합니다. 그와 발맞춰 SNS, 쿠폰, 광고, GPS 위치정보, 비콘 등에 데이터도 꾸준히 증가합니다. 그 이유는 멀티미디어 콘텐츠 사용에 의한 데이터 증가였죠. 아래의 그래프 처럼 데이터는 급격하게 증가하여 정보의 홍수 시대가 오게되었습니다.
이런 데이터를 거대하고 방대하기 때문에 Bigdata라고 부르고 분석의 대한 요구가 생기기 시작했습니다. 그 전에는 수집하지 않았던 각종 센서(IoT) 데이터의 수집, 저장에 대한 요구사항가 생긴 것이죠. 여기서 빅데이터를 처리할 수 있는 강력한 솔루션이 필요했습니다. 그게 바로 오픈소스 프레임워크인 하둡입니다.
2003년에 Google은 "The Google File System" 및 "MapReduce: Simplified Data Processing on Large Clusters"이라는 두개의 논문을 발표했습니다. 아마도 Google은 구글 파일 시스템에 대한 자신감으로 논문을 공개했을 것입니다. 공교롭게도 이 논문은 결국 하둡이 탄생할 수 있게 했던 단초가 되었습니다.
Google의 논문의 아이디어에 영감을 받은 Yahoo의 엔지니어인 Doug Cutting과 Mike Cafarella는 그 아이디어를 오픈 소스 구현을 만들기 시작합니다. 이 프로젝트를 Doug Cutting의 아들이 가지고 놀던 코끼리 인형의 이름을 따라 "하둡"이라고 지은것이죠.
Hadoop Ecosystem
2006년 더그 커팅에 의해 Hadoop이 발표되고 처음에는 HDFS(하둡 분산 파일 시스템), 맵리듀스, YARN 등의 아키텍처를 가지고 있었죠. 저도 맵리듀스를 구현하는 개발을 해보기도 했으니까요. 하지만 이제 더이상 그런것을 배울 필요는 없습니다. 개념만 알면됩니다. 실제 맵리듀스로 개발하지는 않으니까요.
그 이후로 Hive, Hbase 등 빅데이터 분석 및 처리를 위한 오픈 소스들이 발표되기 시작합니다. 대용량 데이터 솔루션이 필요한 산업의 수요가 증가함에 따라 하둡 생태계는 이러한 한계를 해결하기 위해 하나하나 확장되었다고 보면 되겠습니다. 그렇게 진화하여 지금의 Hadoop Ecosystem을 이루게 되었습니다.
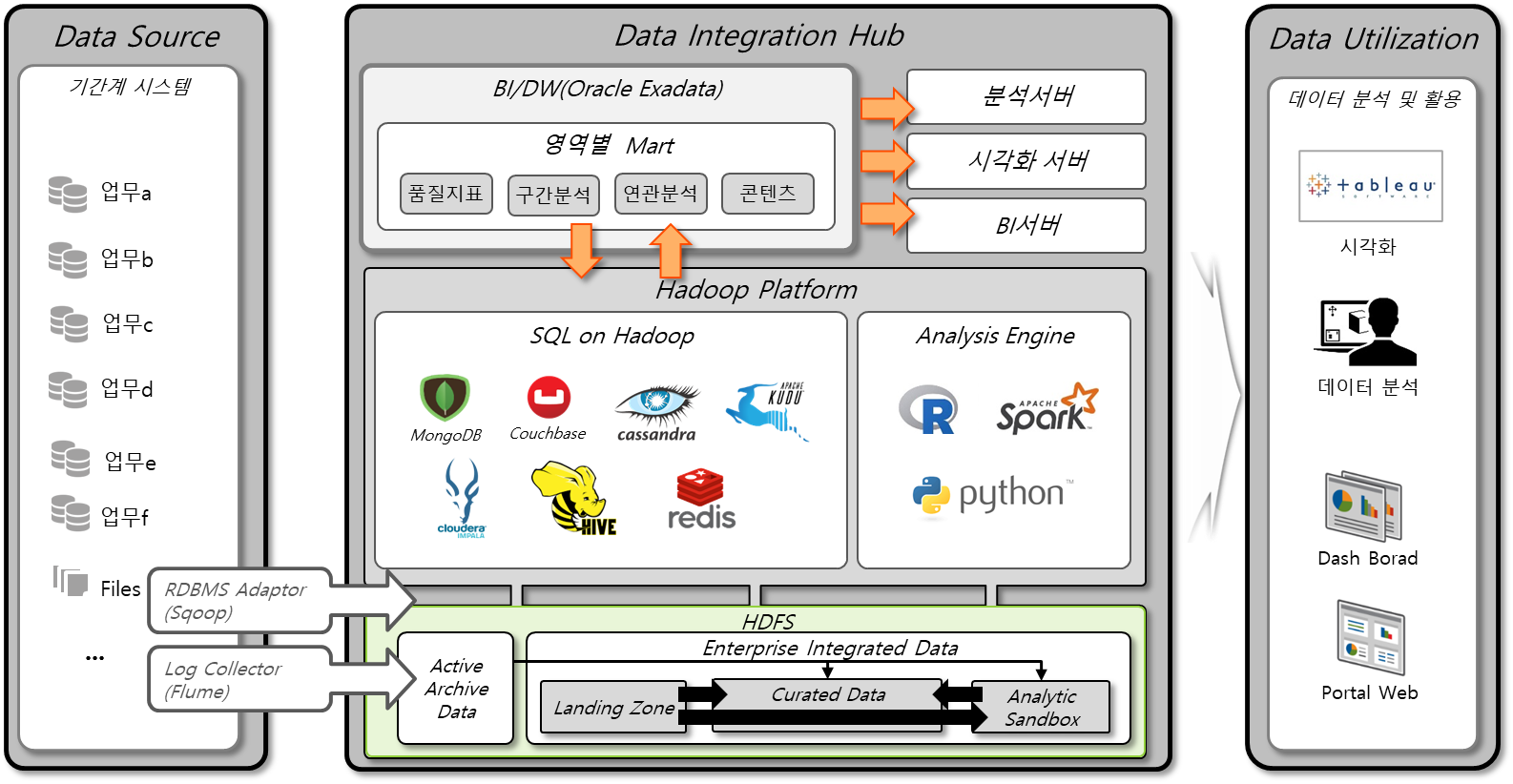
Hadoop의 주요 특징
1. 대용량 처리
- Hadoop은 대용량 처리를 위한 목적으로 만들어졌습니다. 그런데 Big한 데이터를 처리하기에는 기존 DBMS 방식은 너무 비용이 높았습니다. 하둡은 어플리케이션, 트랜잭션 로그 등 Big Size 데이터 처리가 가능합니다.
2. 분산(병렬) 처리
- I/O 집중적이면서 CPU를 많이 사용하는 작업에서 멀티 노드로 부하를 분산하여 처리가 가능합니다. Read/Write의 성능에 최적화 되어 있습니다. 그래서 Update는 권장하지도 않고 안된다고 생각하는 것이 좋습니다.
3. Scale Out
- DBMS는 하드웨어 추가 시 성능 향상이 Liner하게 향상되지 않습니다. 하지만 Hadoop은 장비 증가와 성능이 Linear에 가깝게 향상합니다.
4. 비용 절감
- Apache Hadoop은 오픈소스로 무료입니다. 물론 버전관리 등 필요해 클라우데라와 같은 유로 솔루션을 사용해야 하기도 합니다. 하지만 Intel Core 머신과 리눅스는 상대적으로 저렵합니다.
Hadoop 관리 솔루션 비교
Hadoop 솔루션들은 시간이 지남에 따라 프리미엄 유료 고객이 증가하고 여러 산업 분야에서 파트너십을 맺고 있었습니다. 하지만 클라우드 시대가 오면서 위협을 느끼고 Cloudera가 Hortonworks와 합병하게됩니다. 결국 Cloudera, MapR 2강 구도가 되었습니다. 밴더들은 모두 배포판의 무료 버전을 다운로드 할 수 있습니다. 문제가 발생한 사용자를 돕기 위한 지원 커뮤니티 운영하고 있어 필요시 이용 가능합니다.
| 구분 | Cloudera (CDH) | MapR |
| 특징 |
•350여 고객사와 Hadoop 에코 시스템에 적극적인 코드 공헌을 통해 혁신적인 툴을 개발
•Cloudera Manager라는 관리 콘솔을 사용하기 쉽고 체계적 방법으로 모든 정보를 표시하는 풍부한 사용자 인터페이스로 구현
|
•Cisco, Ancestry.com, Boeing, Amazon EMR과 같은 주요 기업은 Hadoop 서비스를 위해 MapR Hadoop 사용
•Name Node 아키텍처가 없기 때문에 MapR Hadoop은 처리 노드에 메타 데이터를 저장하기 위한 방식을 사용
|
| 장점 |
•Cloudera Impala와 같은 유용한 도구
•다양한 기능과 사용자 친화적인 인터페이스
|
•다중 노드 직접 액세스가 가능한 가장 빠른 Hadoop
|
| 단점 |
•CDH는 MapR Hadoop 보다 상대적으로 느림
|
•MapR에는 Cloudera로 좋은 인터페이스 콘솔이 없음
|
마무리
새롭고 다양한 데이터들이 시대에서 하둡은 새로운 기술을 많들고 다양한 사례들을 경험하고 있습니다. 하지만 한편에서는 클라우드라는 강적이 있습니다. 클라우드 수요가 늘어나면서 하둡도 클라우드 안으로 들어가 하나의 서비스로 제공되는 경우가 늘어나고 있습니다. 위협적인 일이죠. 예를 들어, ECR이나 클라우데라의 EDH(Enterprise Data Hub)처럼 말이죠. 하지만 하둡이라는 기술은 여전히 사용되고 있습니다. 또 하둡이 빅데이터의 시대를 지평을 열였던 역사적 기록은 그대로 남아 있습니다.
'데이터아키텍처' 카테고리의 다른 글
| [SQLD] SQL 비교연산자(관계, 논리), IN, OR, AND, NOT, Exists (58) | 2023.11.16 |
|---|---|
| [SQLD] SQL의 이해 및 구문 (2) | 2023.11.15 |
| 인메모리(In-memory) DB 특징과 종류 비교 (0) | 2023.11.13 |
| NoSQL의 특징 - RDBMS와 어떻게 다를까? (0) | 2023.11.10 |
| Sybase IQ 특징 및 장단점 - Column-wise, Bit-wise Index (0) | 2023.11.09 |


